Fresh data insights from Automattic.
Dive into our blog where we turn complex data into clear, actionable insights. Stay tuned for fresh perspectives and expert advice from the heart of Automattic’s data team.
-
Two Weeks at AI Enablement, NYC
Last month I spent two weeks with Cohort 3 of Automattic’s AI Enablement program: fifty Automatticians from product, design, engineering, data, and ops, sharing one room in New York. Notes from the cohort: how we learned from each other, the patterns in everyone’s AI workflows, and three things I built.

-
Move Fast and Don’t Break Things: Shipping the Simplenote MCP
When Automattic recently launched a month‑long hackathon, engineers Mark Biek and Evan Tobiesen knew exactly what they wanted to work on: the Simplenote Model Context Protocol (MCP) server. Neither Mark nor Evan works in data science, so measurement might have been the easy thing to skip. Instead, they shipped a product with built‑in measurement from…

-
From Messages to Episodes: Building Better Recall for AI Support
Our customers do not think of support as isolated chats. They think in terms of things they are trying to get done: connecting a domain, changing the look of a site, launching a store, fixing checkout, recovering access, or understanding a bill. That creates a challenge for an AI support assistant. If a customer returns and says: Let’s…

-
Bringing Metadata to Life at Automattic with OpenMetadata
The metadata problem at scale Automattic’s data ecosystem is large and highly interconnected: thousands of Iceberg tables and views queried via Trino, thousands of Airflow tasks producing and updating them via Spark jobs, and a growing catalogue of Looker and Superset dashboards and charts on top. Most of the information about these assets exists somewhere, scattered…
-
The WooCommerce Plugin Playbook: What Successful Stores Install, and When
Most plugin advice online is opinion‑dressed‑as‑fact: a list of “top 10 must‑have WooCommerce plugins,” usually written by someone selling one of them. We looked at hundreds of WooCommerce merchants who started a store in the past 12 months, and found a clear four‑phase pattern. At the same four points in their growth, stores reach for…

-
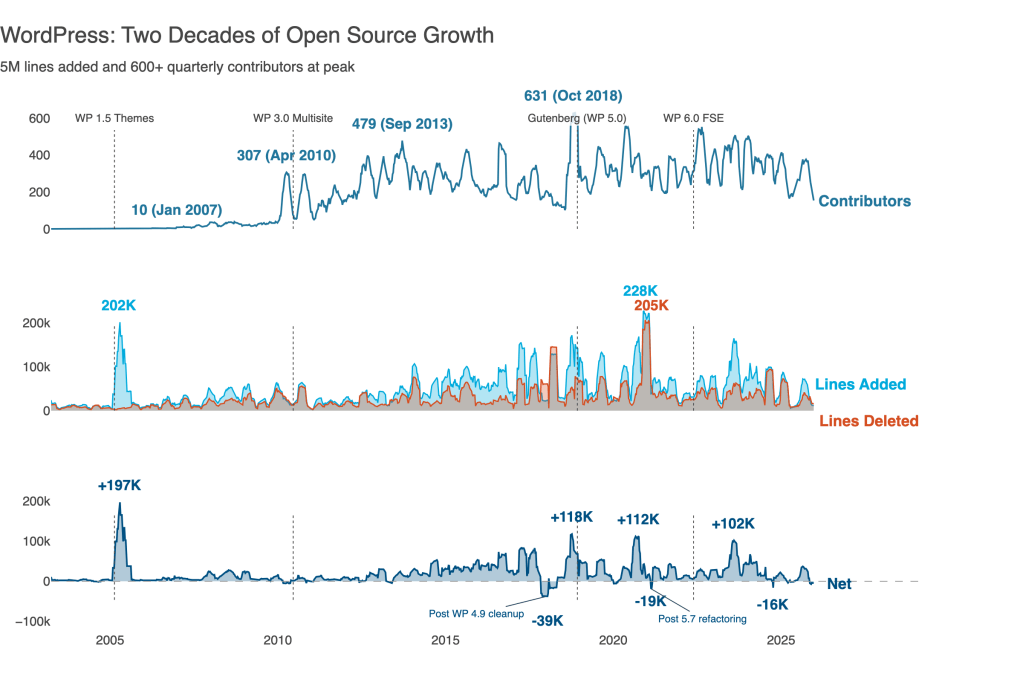
From Default to Delightful: AI-Assisted Data Visualization
I can never remember the exact syntax for visualization libraries. AI changes this. Now I describe what I want in natural language, iterate in conversation, and let the model handle the boilerplate. Five prompts transformed default charts into a visual story of WordPress’s 20-year evolution.
-
AI-powered Typo Hunting: Trust Your Docs, Readers Will
Paulina explains how she proactively addresses the typos in Jetpack.com support pages. She developed an automated solution using the WordPress.com API and GPT-4o model.

-
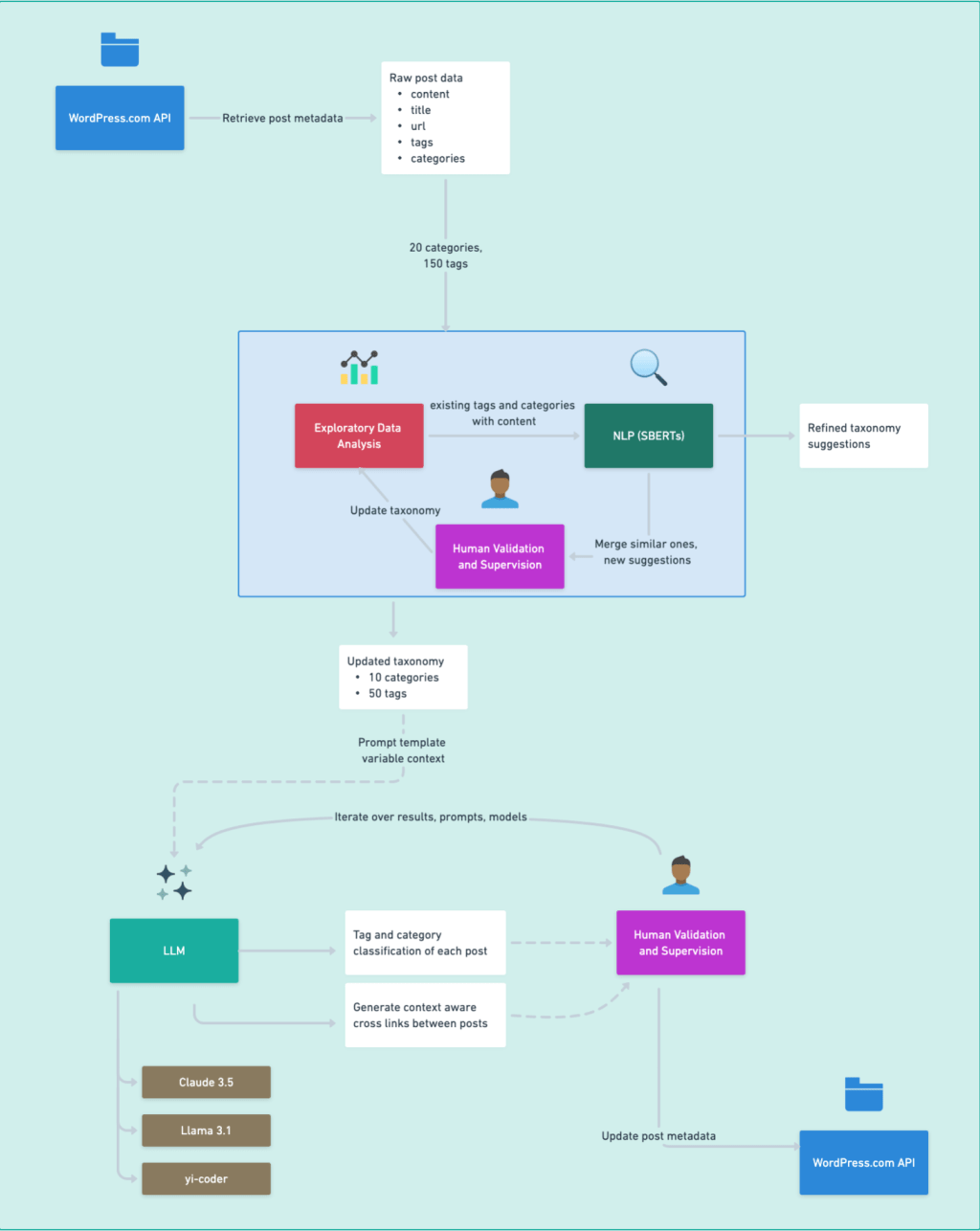
Organizing data.blog content via NLP and LLM
The redesign of data.blog aimed to enhance content discoverability by making category and tag pages more prominent. We re-imagined the blog taxonomy developed over ten years. Using NLP and LLM techniques, we analyzed categories and tags to consolidate and improve on clarity and relevance.
-
New data.blog is here: Designed for Discovery
The new data.blog has launched with a refreshed visual design and improved user experience. Key enhancements include a prominent search bar, better-organized categories, and an updated logo. The redesign aims to facilitate navigation and inspire community engagement for both new and existing authors while encouraging content exploration.

-
Data Talks & Conferences Recommended by Automatticians
This post highlights specific data conferences and talks recently recommended by Automatticians (employees at Automattic). Staying informed is key in the fast-evolving field of data science. At Automattic, we value continuous learning and regularly attend conferences and talks that advance our understanding and skills. This post shares a curated list of events and talks that…

