As a fully distributed company, Automattic has always adopted a unique, mostly asynchronous way of communication. Among our most widely used communication tools, P2 is a WordPress plugin and a platform for teams to discuss ideas, share project reports, and collaborate transparently. You can basically think of it as Automattic’s internal blogging network, where people can both consume and create content that’s relevant to their work. The best part is that it works asynchronously: you can read and write P2s at your own convenient time. In total, the whole company writes about 6k P2 posts and 12k P2 comments per week.
With this vast amount of information, it can often be challenging if not impossible for every Automattic employee (a.k.a. Automattician) to be on top of everything. Despite the existence of a search engine and a recommender system for P2, Automatticians still experience and report fear of missing out (FOMO) on P2 content. During a hack project at the recent yearly cross-division data+ meetup, a couple of data and machine learning folks (Anand N., Andrii N., Fırat G., Jessie R., Jie B., Nick P.) decided to tackle this long standing problem from a data perspective, and came up with a new solution that surfaces more personalized and relevant P2 content.
Hack Project: We ran a hackathon at a recent data-focused cross-division meetup. All participants were split into groups of roughly 5-6 people; each group worked on a predefined project for 3 days. These projects were either related to the day-to-day work of data professionals, or required certain data skills. To encourage cross-team collaboration, we made sure that each group consisted of people from different teams.
The Problem
Automatticians have too many P2 posts to read, and there is a constant fear of missing out, which makes the reader lost and clueless about where to start or stop.
A typical P2 reader has usually encountered at least one of the following situations:
- I never know if I’m done reading P2’s.
- I don’t have a good way of saving P2’s to read / reference later.
- I don’t know what my team or division feels is important.
- I don’t know if there is a conversation happening in the comments thread that I’m not aware of.
- I don’t know if there is a conversation happening on something I’ve already read or commented on.
- When I come back from vacation, I never know what’s important for me to read right away.
The goal
We aim to build a better way to discover and consume P2s. The new solution would ideally surface all (and only) the most relevant content for each reader, such that they’re able to consume the most important information in a small amount of time, and can be confident that they’re mostly up-to-date after the reading.
The Proposed Solution
There already exists an internal P2 aggregator (called P2 Swarm) that surfaces relevant P2 posts from P2s the reader follows. It, however, has some major pain points. The most common feedback we hear is: the content is not relevant to me; the tool doesn’t remember the content I’ve already read; no explanation of why a certain P2 is recommended to me.
With these problems as our guide, we set out to build a new version of the P2 Swarm tool, where the recommended P2 content is both personalized and updated in real time. The new tool also keeps track of which posts the reader has already seen.
We’ll dive a bit deeper into individual components in the following.
Data sources
We defined the following three sources as the signals for the recommendations. We retrieve each content stream separately via Elasticsearch queries, and then build a single feed with a weighted mix to do sorting.
- Collaborative filtering: Posts from your followed P2s that were engaged or authored by the most similar readers as you (i.e. they previously engaged on the same P2 posts as you did). This is much like the classical collaborative filtering algorithm for recommender systems.
- In-network: P2 posts engaged by people in your network (either from the primary team, e.g. Spirit, or the parent team, e.g. Feeds, Engagement, Notifications). These posts can be from P2s not yet followed by you, and therefore offer a view into what like-minded people as you are reading/talking about.
- Globally popular: The most engaged P2 posts across the whole company. This is to draw readers’ attention to widely popular topics that are potentially relevant to everyone.
Architecture
All P2 data live on our Elasticsearch cluster. In addition to posts’ content, Elasticsearch also has the data of likes and comments.
We make use of the P2 impression data on a separate MySQL database to keep track of the posts already seen by a specific reader. We retrieve the team network data from a Hive table on the Hadoop cluster.
Our overall architecture makes heavy use of Elasticsearch. This design has the advantage of retrieving real-time engagement data, and producing on-the-fly recommendations. At the same time, it keeps the project well scoped and the tech stack lean.
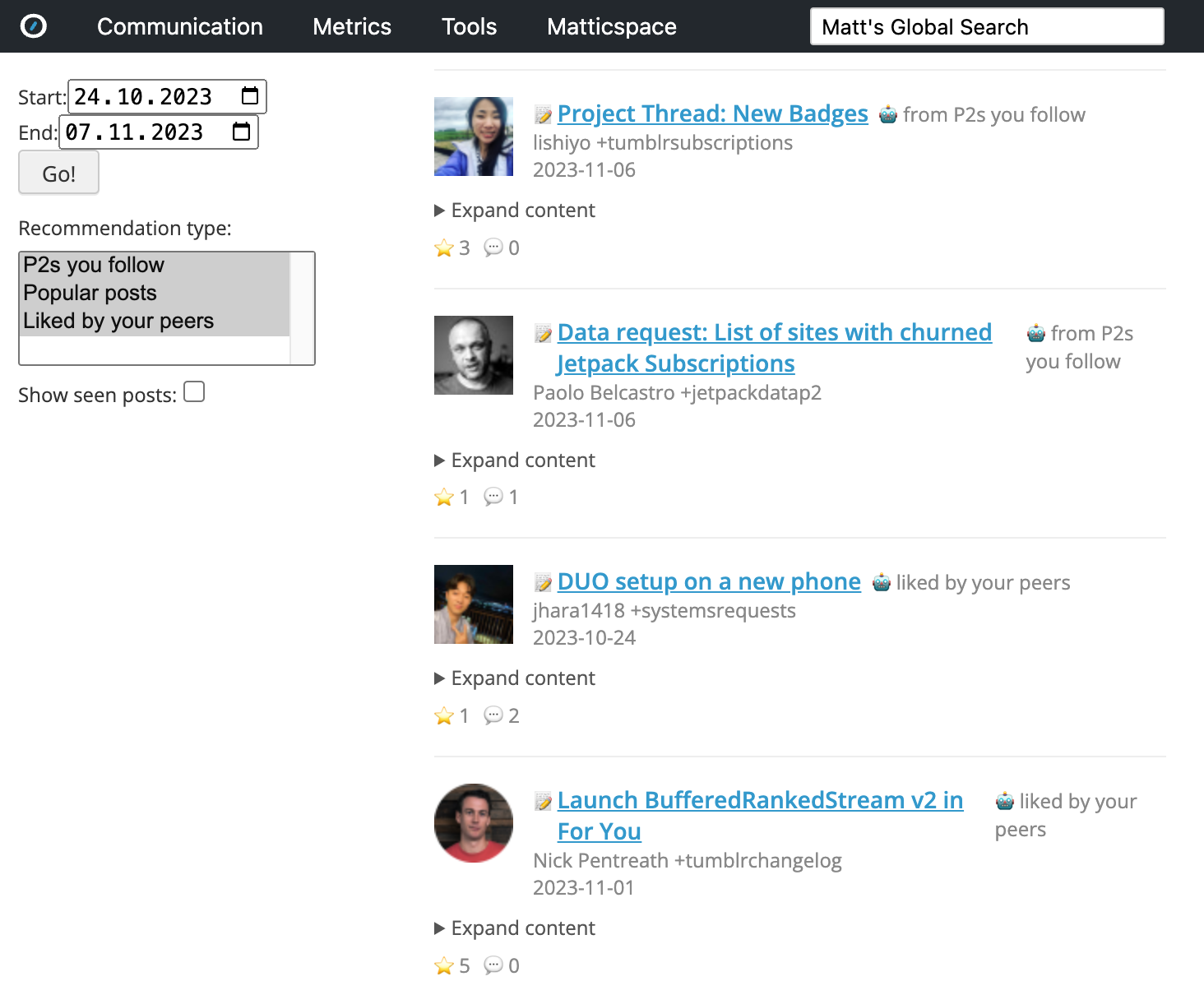
We built a new UI with different filters on top of an internal dashboarding tool called Mission Control (MC). Like the original P2 Swarm, our new tool, code-named P2 FOMO, accepts optional date range input from the reader to filter the posts by creation date.
We also have the following filters in addition:
- P2s you follow
- Popular posts
- Liked by your peers
- Posts already seen by you
The reader has the choice to turn these options on or off to filter the feed content as needed.
AI summary
We also added summaries of individual posts to the P2 FOMO UI, by calling a self-hosted Llama2 model for text summarization. We iterated on multiple prompts and settled on the following one:
Act as an editor in a news website to create a succinct summary of <post text> and return bullet points.
- Only respond with the summary and make sure not to provide any extra comments.
- Use bullet points.
- If there is any, include the call to action phrase in the summary.
- The summary is 400 characters max.
- Ensure to not repeat the same information.Since the latency of generating the post summary is pretty high at the moment, we realized that we need offline processing to prepare the summaries in advance, in order to have a fast loading time of the UI and a smooth user experience.
How we worked
Jessie, our JavaScript guru, helped us set up an iCloud shared folder to sync up content from our local machines, and provided a place where we can all access the code. We split the work in parallel and often ended up shouting out loud what each of us was working on, to make sure we didn’t edit the same file. While this definitely felt primitive and not as productive as the git workflow, it worked relatively well and surprisingly helped boost the team feeling and spirit as well.
We also ran backups and synced every 5 mins, which is sometimes more or less reliable. There were occasions when we got weird errors and realized the code was not synced up, because Jessie’s laptop was offline.

Closing words
At the end of the hack project, we managed to wrap up a working version of the P2 recommendation tool, and had deployed it internally. Our fellow Automatticians have since then expressed a large amount of excitement about the tool, and also provided us with some helpful feedback.
Interesting user feedback and ideas for possible follow-up work include recommending personalized comments (in addition to posts), and adding a feature to follow specific users/teams.
Overall, this hack project was a lot of fun and also a great learning experience for everyone. We all feel happy to have contributed to a communication tool that’s used by the whole company every day. We hope our data-informed feature can add little steps to higher productivity and a more enjoyable working culture within Automattic.
