When redesigning data.blog, our primary goal was to make it easier for readers to find great content.
One of the ways readers do this, is using the site taxonomy – the categories and tags that are used to organize the blog posts on the site.
As data.blog grew over the past 8 years, we accumulated an excessive number of categories and tags. To address this issue and enhance content discoverability, I used Natural Language Processing (NLP) and Large Language Model (LLM) techniques to organize our content taxonomy.
NLP is a field of artificial intelligence (AI) that focuses on enabling computers to understand, interpret, and generate human language, while LLMs are a type of AI model trained on vast amounts of text data to perform various language tasks.
I developed Python scripts that leveraged the following tools:
- The WordPress.com API to retrieve post content and edit post metadata
- The Anthropic API to query Claude 3.5, an AI assistant
- Ollama, a tool that allows you to run open‑source LLMs locally
- The Haystack framework, an open source AI framework library, to build the retrieval‑augmented generative pipelines
View the Python code for this project: WordPress.com Blog Metadata Organizer
Challenge
data.blog publishes on a wide range of topics, like network analysis, Elasticsearch, and data visualization, and content like interviews and book reviews. As Automattic expands into new business areas, the nature of the company’s data work is expected to evolve. With different editors and authors publishing posts, a rich taxonomy has developed.
However, the taxonomy needed pruning. A new website design highlighted discrepancies in spelling (e.g., ‘time series’, ‘timeseries’, or ‘time series analysis’) and the use of synonyms in our tags (e.g., ‘ab testing’, ‘a/b testing’, ‘experimentation’). Sometimes, the same value was used for both a category and a tag. This makes it hard for readers to find the content they want. And it makes it challenging for authors to choose tags and categories for their posts.
Approach: A Three‑Step Process
The data.blog team wanted to build a consistent and lean taxonomy. As a volunteer, I saw this as an opportunity to apply my skills and learn new techniques. This involved:
1. Exploring and Analyzing: First, I examined the existing categories and tags, identifying inconsistencies, redundancies, and areas for improvement. This step involved understanding the current state of the taxonomy and determining which elements to keep, merge, or remove.
2. Updating and Consolidating: Next, I updated the taxonomy by merging similar categories and tags, removing irrelevant or rarely used ones, and creating new categories or tags where necessary. This step streamlined the taxonomy, making it more coherent and user‑friendly.
3. Enhancing with AI: Finally, I leveraged NLP and LLM techniques to further refine the taxonomy and identify meaningful connections between posts. This involved using AI to suggest new tags, categorize posts more accurately, and generate contextual internal links to improve content discoverability and user experience.
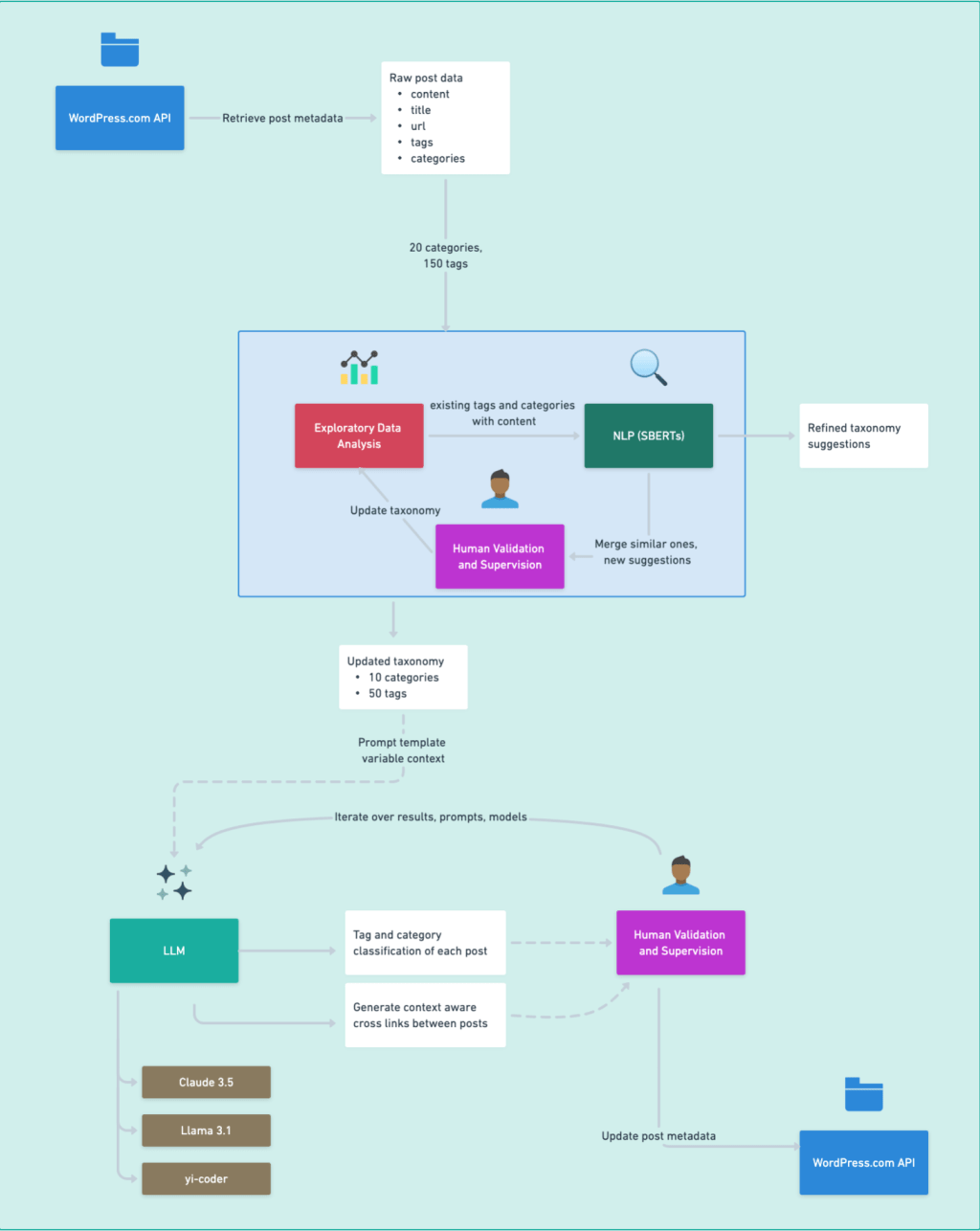
The following diagram illustrates the workflow of our taxonomy cleanup process, from data retrieval to continuous improvement

Deep Dive: Organizing Metadata
Over the years, we accumulated 150 tags and 20 categories on our blog.
Removing some categories based on low usage or merging close variants was easy.
Some categories weren’t being used effectively. For example, the “Data at Automattic” category was originally intended to feature posts related to data work being done at Automattic, and keep it separate from interviews, book reviews, and topics not specific to the company. But over time, this category ended up including random sub‑categories, and that meant that at least half of our posts could fall into this category.
The taxonomy issues with tags were even more pronounced. There were often 2‑3 variants of the same tag, spelled differently or using semantically identical terms (i.e. “work life balance”, “Work‑Life Balance”, “working conditions”). There were overlaps in tag meanings, such as “analysis”, “data analysis”, and “descriptive data analysis”. Many tags were generic or simply buzzwords like “big data”, “data”, and “work”. Finally, many tags were used for only one post. This created friction for readers, as well as for authors.
To address these issues, I used SentenceTransformers (SBERTs). SentenceTransformers is a Python library that provides pre‑trained models for generating sentence embeddings, which are numerical representations of text that capture semantic meaning. I experimented with different language models, including the small and fast all‑MiniLM‑L6‑v2 (the most popular one) and the higher‑performing dunzhang/stella_en_1.5B_v5.
These were used to create vector embeddings of post content with existing tags and categories. I computed similarities between tags and categories and identified new ones. The output was a set of 10 categories and 50 tags that better represent the blog’s content, providing a foundation for improved content organization.
I used these SBERT models to classify posts into categories and tags. Two particularly impressive model responses are worth highlighting. First, the model found 6 posts where we could use the tag “Bias in AI”, despite not using this tag originally and using that term in a single post title. Second, we had a couple of single‑use tags for company names like Amazon, Google, and Zalando. The model consolidated these under the “Tech Industry” tag.
However, these models kept overusing some categories and tags. Instead of refining the models, I decided to apply LLM technology to this problem.
Leveraging AI for Taxonomy
I built an LLM pipeline to assign tags and categories to each post using the previous step’s output. The pipeline includes validation of LLM responses that extracts tags and categories from the content. The prompts greatly improved the results. Designing a structured flow, repeating key parts, and providing a schema for the desired output format was very useful.
The pipeline looks as follows. There’s a loop on the output validation, iterating invalid replies with error messages back to prompt_builder. The prompt_builder is a crucial component of the pipeline, responsible for constructing the input prompts for the LLM. It takes into account the post content, the desired output format, and any error messages from previous iterations to create prompts that guide the LLM towards generating accurate and relevant tags and categories.

There are two locations where you can run LLMs: hosted in the cloud or locally on your computer. I compared the performance of local Ollama models with the cloud‑hosted Claude 3.5 Sonnet at generating new tags and categories. Both local and cloud models performed well, but the local model struggled with producing accurate JSON schema output, often resulting in missing commas or brackets. In contrast, Claude 3.5 Sonnet, being a more powerful model, generated flawless output. Hosted models involve fees based on processing power. Updating the taxonomy of 100 posts using Claude 3.5 Sonnet cost about $2.
Impressively, Claude even suggested a new category for a post, despite it not being in the provided list. Since this category was only applicable to one post, I decided to use it as a tag instead of a category, overruling Claude’s suggestion. This experience highlighted the importance of balancing AI suggestions and human oversight.
Connecting the Dots: Generating Internal Links
As a final step, I used LLM to generate internal links between semantically related posts.
Internal linking improves user experience by making content more discoverable and boosts SEO. The LLM suggested contextually relevant links, anchor text, and placement within the source post. The generated sentences blend naturally into the surrounding context, demonstrating the effectiveness of the LLM.
I demonstrate the LLM suggestions with the reasonings in green below
In this case with Madison’s interview, LLM suggests adding the highlighted line to link to Menaka’s interview.
[…] A number of contributors from the community have provided significant contributions and improvements! Being able to do all our work in the open has been a huge asset.
The reasoning sounds sensible:
Explanation: This link connects Madison’s positive experience at Automattic to Menaka’s similar sentiments, highlighting the company’s support for women in tech roles.
I decided not to use AI suggestions to rephrase the interview responses, as I want to preserve the original wording and avoid misrepresenting what was said.
In another case, the LLM generated a link from an earlier interview with Anna to a more recent one — connecting her story from the previous post.
[…] I found the transparency, the dedication to open source, and distributed work very appealing, and saw working in a remote team as a fantastic way to grow as an analyst and a professional overall. I now lead the central reporting and infrastructure team I’d originally joined in 2019, and I couldn’t be more excited about our mission to empower business leaders at Automattic to make the right choices about the right things, with confidence.
You can read more about my journey and experiences as Head of Data at Automattic in this interview
Another example of connecting posts with a 6‑year gap:
During a series of analyses I did for the HR team about how Automatticians communicate with one another, I found out that the GM is also really good for our communication.
This communication density is crucial for our distributed work environment, helping to combat the fear of missing out (FOMO) on important information.
I received the following reasoning from the model — which makes sense!
Explanation: I inserted a link to the target post in a relevant section discussing communication at Automattic. The link provides context about how communication density is important for distributed teams and ties into the discussion of the Grand Meetup’s effect on communication in the source post.
Again, I observed higher quality results with Claude 3.5 Sonnet. It cost around $1 to generate the new links for 23 post pairs.
Learnings
Balancing automation with human oversight posed a challenge. While LLMs suggested categories and tags, they sometimes produced inconsistent or irrelevant results.
Although we could have manually categorized 100 posts, this exercise provided valuable learning and a scalable solution for larger datasets. I enjoyed the challenge and learning opportunity!
Key takeaways include:
- The importance of prompt engineering, model selection, and the capabilities of even smaller language models for classification tasks was key
- The LLMs followed prompts effectively and generated links between posts with natural flow, especially with Claude 3.5.
- Iterative refinement in taxonomy development, considering both data science principles and editorial direction, was crucial.
Balancing automation with human oversight posed a challenge. While LLMs suggested categories and tags, they sometimes produced inconsistent or irrelevant results. For our 100-post scale, human supervision was efficient and impactful. However, at a larger scale, implementing a robust validation system, expanding on the simple JSON schema validation I have in code, would ensure LLM suggestions remain relevant and adhere to our taxonomy goals.
I enjoyed working with the Haystack framework, an open‑source toolkit for building search systems. Its modular design allowed me to quickly experiment with different document stores, retrieval methods, and NLP models. By leveraging this well‑designed tool, I could focus on the high‑level architecture of the taxonomy management system, which reinforced the value of using open‑source solutions to accelerate AI projects.
Looking Ahead
We’ve just launched our new design with a streamlined taxonomy. We plan to gather feedback from readers and authors on the use of tags and categories. We hope it improves the reading experience.
Using Parse.ly, an Automattic content analytics platform, we plan to track the recirculation rate (views referred / page views) to assess navigation ease and content discoverability. A high rate suggests visitors can find posts easily. We’ll monitor this metric and observe changes in reader navigation patterns.
I invite readers to suggest improvements and questions about the process. Do you see any missing tags or categories? Is there any part of the taxonomy that still needs improvement? Let us know in the comments!
Thanks to Shannon, Daniel, Jie for the reviews and edits on this post!


Leave a comment