The WordPress.org plugin directory has been significantly rebuilt over the past year and should go live soon (test site). Many from across the WordPress community helped with this effort. I focused on improving plugin search relevancy. This was a great learning experience on how to build more relevant searches for a couple of reasons:
- There is a decent volume of search traffic (100,000 searches per day and over 500k unique search queries per month).
- The repo is small enough to iterate easily (45k total plugins) and yet has enough users and use cases that it can be pretty complex. We went through five major iterations on how to index the data.
- A lot of people care and have opinions about how plugin search can be better. This makes for a great opportunity to learn because it is easy to get lots of feedback.
Despite building search engines with Elasticsearch for many years, my opinion on how to structure an Elasticsearch query and index content changed a lot because of this project. This post describes my latest opinions.
Background on Plugin Search
In surveys about WordPress, the community regularly rates the plugin ecosystem as both a top strength and a top weakness of WordPress. Plugins give users flexibility in building websites, but can also be a source of frustration due to updates, incompatibility, and getting support when something goes wrong.
The most popular plugins are installed on millions of websites and are often built and maintained by teams of developers. But many plugins are small; they fill many different niches, and have varying levels of developer support. Sometimes they solve a problem really well, sometimes they are abandoned and rarely used.
Algorithm Philosophy
Ultimately, a search algorithm is driven by design opinions about the problem you’re solving. In looking at the data and having discussions over the years, I’ve developed some opinions about plugin search:
- We design search primarily for end users, not for developers. Developers make up a small percentage of the 100k searches each day.
- We steer end users toward plugins that are most likely to give them the best WordPress experience. This doesn’t mean simply matching text, but rather trying to answer the question implied by the text: Which plugin will solve problem X for me?
- Plugins shouldn’t just solve the problem right now; they should still solve the problem a year or two from now. Past history is the best indicator we have of a plugin’s future.
- Search terms indicate demand for a feature, and active plugin installs indicate the supply side of that equation. If 10k people per year want a particular feature, we should recommend plugins that can support that volume of new users.
I expressed this on the search relevancy ticket and I know that some of it is controversial. Opinions usually are. Let me try an example. (Disclaimer: I’ve worked on Jetpack Stats in the past.)
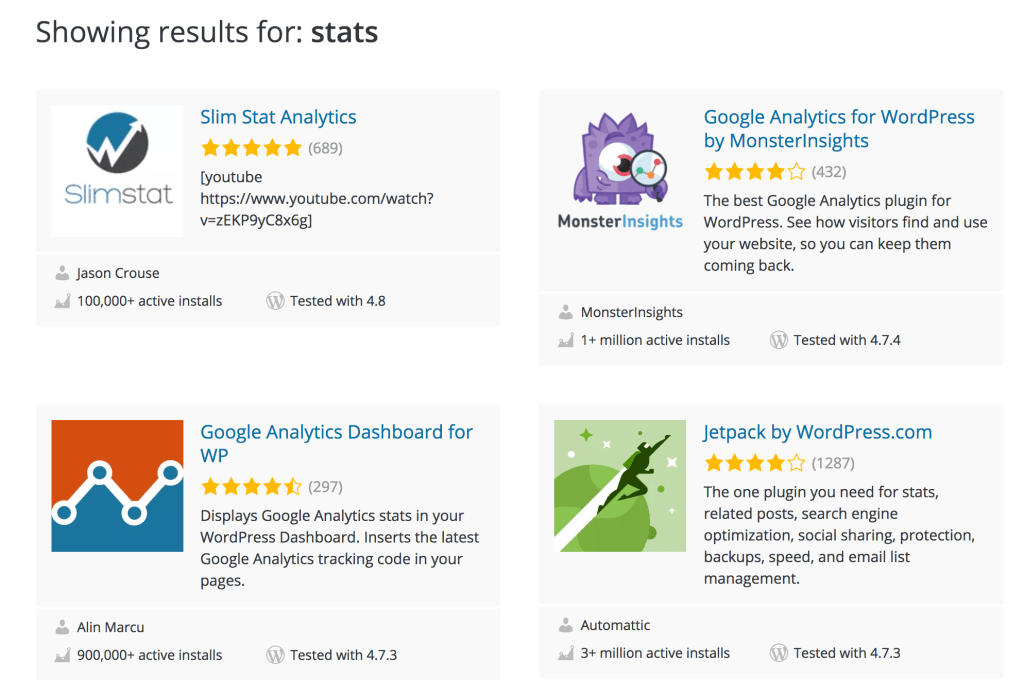
Users search for “stats” 93 thousand times a year. (It’s the 13th most frequent search on the plugin directory.) Here are the top four search results with the old algorithm:

The old search suggests that 90 thousand people per year go and install plugins that collectively, have only proven that they can “handle” 20 thousand users. Scaling stats as a service (as many plugins do) can be quite hard and expensive. Sending 90k new users per year to these plugins seems unrealistic. Even if the plugin doesn’t work as a hosted service, it still needs to scale answering support requests from end users.
Let’s compare that to the top four suggestions from the new search algorithm:

These install counts make a lot more sense given that we’re getting 93k searches per year. Collectively, these four are already used by millions of sites, so sending a hundred thousand more sites toward them each year will not overwhelm them. Presumably users we direct toward them will have a good experience with those plugins — as millions already have.
In improving the fidelity of search results, it’s not just a question of how we satisfy a single user’s search query, but how we satisfy thousands of users for each unique search term: which plugins will support that volume of users and their requests for support? Which are most likely to give all of these users a great WordPress experience?
Evaluating Results
To build relevant search, you need a plan on how to iterate on evaluating search results. In the previous iteration of plugin repo search, we didn’t have good click data for evaluating search, nor did we have a way to evaluate it on live traffic, so I used a few sets of searches for my testing:
- “Important” searches. This was a list of about 50 searches. Important searches include some searches from the top 10 and some that I and others found interesting. A number of the searches that were cited as feedback on the search ticket ended up in here (“responsive slider,” “event,” “import,” “transport,” “glotpress”). We focused particularly on searches that were ambiguous or were words that would show up for completely unrelated plugins.
- Top 1k searches. This covers 46% of all searches.
- Random 1k from the top 100k: just take the top 100k and randomly select from among them.
- Random 1k from the bottom 400k searches. These are mostly searches that occurred once over the course of two months.
I repeatedly ran the search queries I evaluated against these lists and imported them into a spreadsheet to sort and evaluate them. Because 3000+ searches is way too many to manually evaluate, I tried to focus on a few things:
- Were the “important” searches looking good for the top 14 results?
- Which searches received zero to four results? How many of them were there? (This analysis also led to defining some future work on auto corrections)
- Which searches had the lowest/highest ratio of
active_installsto number of times the search was performed? (I tried to use this as a proxy for the supply vs. demand ratio I mentioned above. I also used a similar ratio for resolved support threads.)
It wasn’t a perfect system, but it allowed me to quickly iterate and evaluate new index mappings and queries. None of these “metrics” were good indicators of performance, but having them let me sort the queries, focus on the outliers, and work to improve the results overall.
Common Elasticsearch Query Patterns
I’ve started to think about the generic structure that I apply when writing Elasticsearch (ES) queries, and how that structure can help me create relevant results.
Over the past year, I’ve settled into some common patterns. The core of searches are almost always a text-matching portion boosted by a number of other signals. The structure also splits the query into three parts: (1) function boosting applied to meta data about the documents; (2) an AND text query that reduces the set of documents that match; and (3) a section that boosts the document scores based on the text of the documents.
So overall, there are three major sections of the query: function boosting, text matching, and text boosting. These all get wrapped together into a single ES query, but let’s discuss the sections separately.
Function Boosting
A search query that is modified by a number of other signals is straightforward:
"query": {
"function_score": {
"query": {
//Text scoring query (text matching and text boosting)
},
"functions": [
//series of functions to multiply the text score
],
"boost_mode": "multiply"
//if any signals are open ended, set a max using max_boost
}
}
For simplicity I’ve left off any filtering of the results to focus just on scoring the documents.
For the plugin search, we use a number of different signals. Initially we adjusted them on an ad-hoc basis, by looking at a single query and making small tweaks. Eventually we discovered that making adjustments for one query would hurt a different query. I found that graphing the functions across the ranges that mattered to me helped a lot. The charts below are from my (very simple) graphing code.
We iterated on the active_installs boosting three times, so it’s a good example.
It started as sqrt( active_installs ):

This had the problem where sqrt increases very quickly when applied to a field that is exponential in nature. Starting from 1, active_installs goes up to 1,000,000. Clearly, 1 million installs is not a million times more important than a single install. But even with a square root we increase much too quickly and give the 1 million plugin 100 times more importance.
And so we switched to ln( active_installs ):

That is better, but we found that there was not enough differentiation between a plugin installed 100k times and one that was installed more than a million times. We often ended up recommending a plugin with 50k installs even though there was one with 500k that seemed like a better option.
This resulted in combining two functions for boosting active installs:
{
"field_value_factor": {
"field": "active_installs",
"factor": 0.375,
"modifier": "log2p",
"missing": 1
}
},
{
"exp": {
"active_installs": {
"origin": 1000000,
"offset": 0,
"scale": 900000,
"decay": 0.75
}
}
}
The exponential turns the logarithmic curve into a mostly straight line from 100k to 1m so that there’s more differentiation in that range. You can see the difference:

Most of the other signals were not this complicated and only needed minor adjustments. Along the way, writing out the actual scoring equation also helped a lot. In the end, our boosting looks something like this:
text_score * 0.375 * log2p( active_installs ) * exp( active_installs, 1000000, 0, 900000, 0.75 ) * 0.25 * log2p( support_threads_resolved ) * 0.25 * sqrt( rating ) * exp( tested, 4.7, 0.1, 0.4, 0.6 ) * gauss( plugin_modified, 2017, 180d, 360d, 0.5 )
Though active installs is important, we also focus on signals that plugin authors have a lot more control over and are behaviors that should lead to a good user experience:
- Resolving support threads.
- Keeping the plugin update to date.
- Testing the plugin on the latest versions of WordPress.
Text Matching
During this project, I decided that the way I’ve been structuring my search queries did not give me enough flexibility when trying to reason about and fine tune the search. In the past, I have been using a text query that looks something like this:
{
"multi_match" : {
"fields" : [
"title.ngram^2",
"content",
"tags",
"author^2",
],
"query" : "post stats",
"operator" : "and",
"type" : "cross_fields"
}
}
Let’s break down these pieces:
- We search across a number of fields, and boost some individual fields. (For example, the author is twice as important as the content because if you match on author you are probably doing an author search.)
- Partial word boosting is very helpful for plugin titles so we use n-grams. My favorite example of this is “Formidible,” a form builder plugin with a name that is slightly too clever to score well in a search for “form.”
- Use an
ANDoperator. The user specified both “post” and “stats.” The docs we return should have both terms in them. This is the behavior users expect. - We match across fields. This way if “stats” is in the title and “post” is in the content, the document will still match. Search will feel broken otherwise.
Often I would wrap the above in a boolean query with this as a must clause, and then add a should clause that would boost the results when we matched a phrase. So if “post stats” is in the doc, it would be boosted a bit.
The above query structure works OK, but I found it very difficult to separate which set of documents were getting matched from how we were scoring those documents. The title.ngram for instance can be a very noisy matching query, but when I tried adjusting it I kept finding other cases that would break. Like most search problems, when something isn’t working well, it’s time to rebuild and restructure your index. So I added a new field called all_content that contained all the text about the plugin: title, author, slug, content, tags, etc. Then I built a query that mostly separated matching documents from boosting the score based on the text of the docs.
The text query pattern became:
"bool": {
"must": {
"multi_match": {
//must match against the content,
// but very low boost so the score is mostly inconsequential
"fields" : [ "all_content_en^0.1" ],
"query": "USER_QUERY",
"operator": "and"
}
},
"should": [
//a series of other queries that are used to boost the results
]
}
Now, document matching is mostly separated from determining which document has the most relevant text. The docs which match our query are determined by the all_content field entirely. This also works great for search as you type. We can build an all_content.edgengram field to match against very efficiently. When all we have is a few characters, the ranking will be determined by this field.
The all_content field always contributes some scoring to our results, but because of the low boost, if any of the should clauses match, then those will completely dominate the scoring. If none of the boosts match though, then this basic query ensures we get some ranking which will mostly get reranked by our function boosting.
Implementation detail: In our case we treat the all_content field as an entirely independent ES field, but Elasticsearch also has a copy_to parameter in its mappings that can be used to implement it.
Text Boosting
When any of the should clauses match, our score effectively becomes the sum of the different queries in the should clause. When debugging individual queries that are not performing well, we can focus on coming up with a new query clause to improve those specific results without worrying too much about the changes affecting the set of documents we’re scoring. It’s still important to test the impact, but in my experience it’s a lot easier to reason about.
For instance, if I see a number of cases where it looks like we want to match a partial word in the title of a plugin, we can add this query to the should list:
{
"match_phrase": {
"title_en.ngram": {
"query": "USER_QUERY",
"boost": 0.2
}
}
}
Because these are n-grams (and it is a 3-5 n-gram field), the boost doesn’t need to be very high to have a strong impact. But because we’re not including n-grams in the must portion of the query, we won’t have as much noise as we did before.
In the end, we now have a much more complicated-looking query, but it was surprisingly easy to reason about how to build it when evaluating specific cases:
"bool": {
"must": {
"match": {
"all_content_en": {
"query": "stats",
"operator": "and",
"boost": 0.1
}
}
},
"should": [
{
"multi_match": {
"query": "stats",
"fields": [
"title_en",
"excerpt_en",
"description_en",
"taxonomy.plugin_tags.name"
],
"type": "phrase",
"boost": 2
}
},
{
"match_phrase": {
"title_en.ngram": {
"query": "stats",
"boost": 0.2
}
}
},
{
"multi_match": {
"query": "stats",
"fields": [
"title_en",
"slug_text"
],
"type": "best_fields",
"boost": 2
}
},
{
"multi_match": {
"query": "stats",
"fields": [
"excerpt_en",
"description_en",
"taxonomy.plugin_tags.name"
],
"type": "best_fields",
"boost": 2
}
},
{
"multi_match": {
"query": "stats",
"fields": [
"author",
"contributors"
],
"type": "best_fields",
"boost": 2
}
}
]
}
I have also been using this same query structure on other projects and so far it’s made iterating on algorithm relevancy much easier.
You can also take a look at how the whole query gets put together in the source code. The actual query also has some interesting customizations for searching in non-English languages given that many plugins do not have good translations to the hundred or so languages that WordPress supports.
Want to help build better search for the Open Web? We’re hiring.



Leave a comment