
Our excellent support is a big part of what makes WordPress.com a compelling platform for so many. Each month, we respond to 60,000 support requests on topics ranging from plugins to mapping existing domains to WordPress.com. Some questions arise several times daily, while others require novel solutions from our Happiness Engineers who have a deep understanding of our products, a skill for asking the right questions, a commitment to support, inventiveness, and creativity.
Recently, in looking at how machine learning and natural language processing could be useful to Happiness Engineers (HEs) in responding to support questions, we discovered two places where these technologies offer value.
First, our Happiness Engineers often rely on tried and true responses to some of the more straightforward questions. We call these pre-defined responses predefs. Many HEs develop personal favorites, and some predefs eventually become part of our best practices based on their ability to succinctly express the answers that users are looking for. In our investigation, our first question was:
Could we develop a more powerful predef mechanism — a predef dictionary capable of generalization that would supply the HE with suggested responses based on best practices?
The figure below illustrates the idea in action.
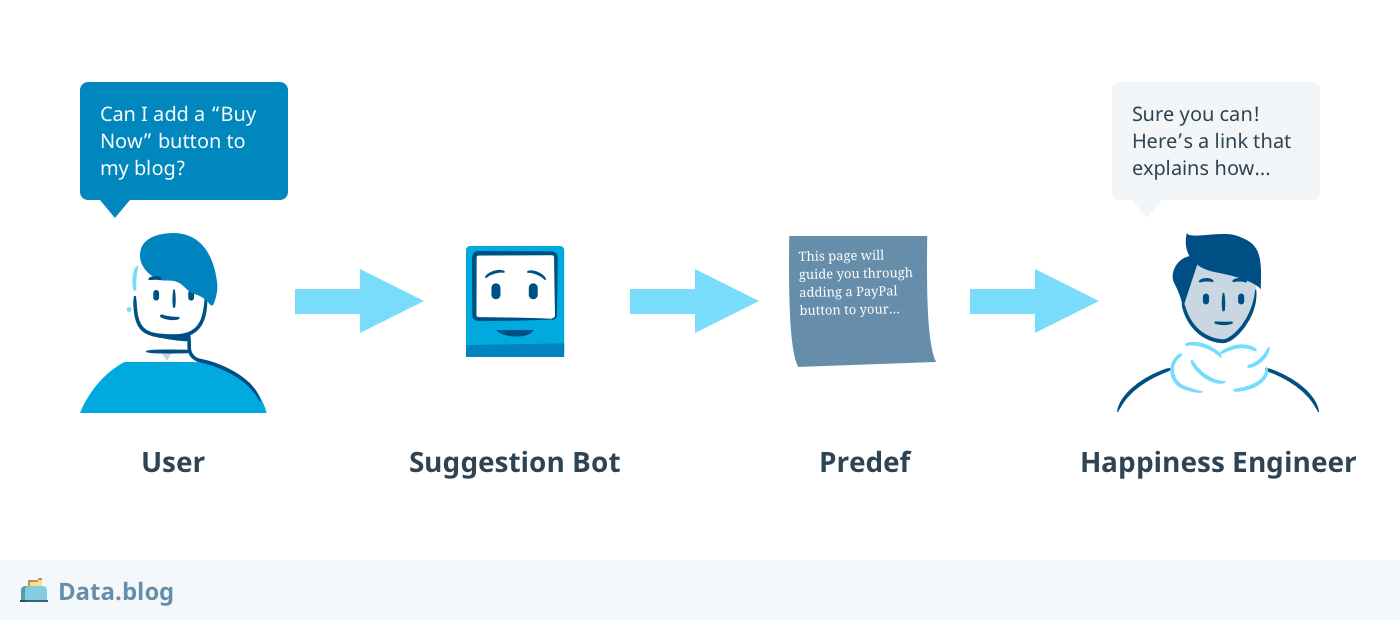
The Happiness Engineer would glance at the suggestion, and if acceptable, could send it to the user or modify it as they see fit. For more complex questions, the suggestion bot (I’ll just call it a bot for short) remains silent while the HE interacts with the user. The bot should be able to recognize when questions are outside its expertise.
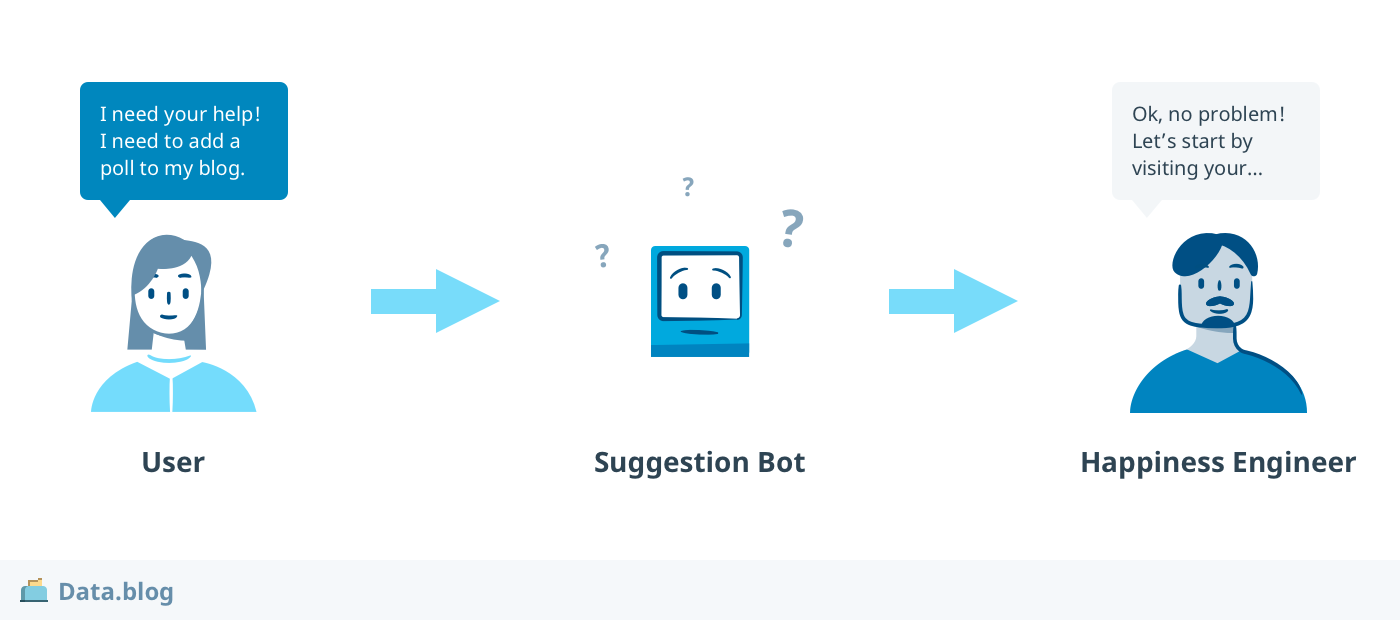
The second important case arises at the end of a chat. HEs tag chats to identify the main issues addressed during the conversation. Our PayPal chat begins with an e-commerce-related question, but could jump to other topics, such as selecting a blog theme, for example. Tagging chat sessions helps us understand how issues are trending, and this information informs both staffing and product improvement. Oftentimes, the need to quickly move from one support session to another means that the chat goes untagged, and valuable information goes unrecorded: automatically tagging each chat not only solves this problem, it inspires the second question:
Could we develop ways to automatically tag a given support conversation?
Both the suggestion bot and auto-tagging rely on a mechanism to classify the chat.
In this post, I’d like to discuss some of the approaches we explored for chat classification — how we collected data, the approaches we used for classification, what worked and what didn’t, and the insights we gained from the process.
What is chat classification?
Both of these applications are really about labeling chats. For response suggestions, the label is associated with a response, and since there may be several types of questions related to enabling a blog for e-commerce, we need finer discernment for response classification.
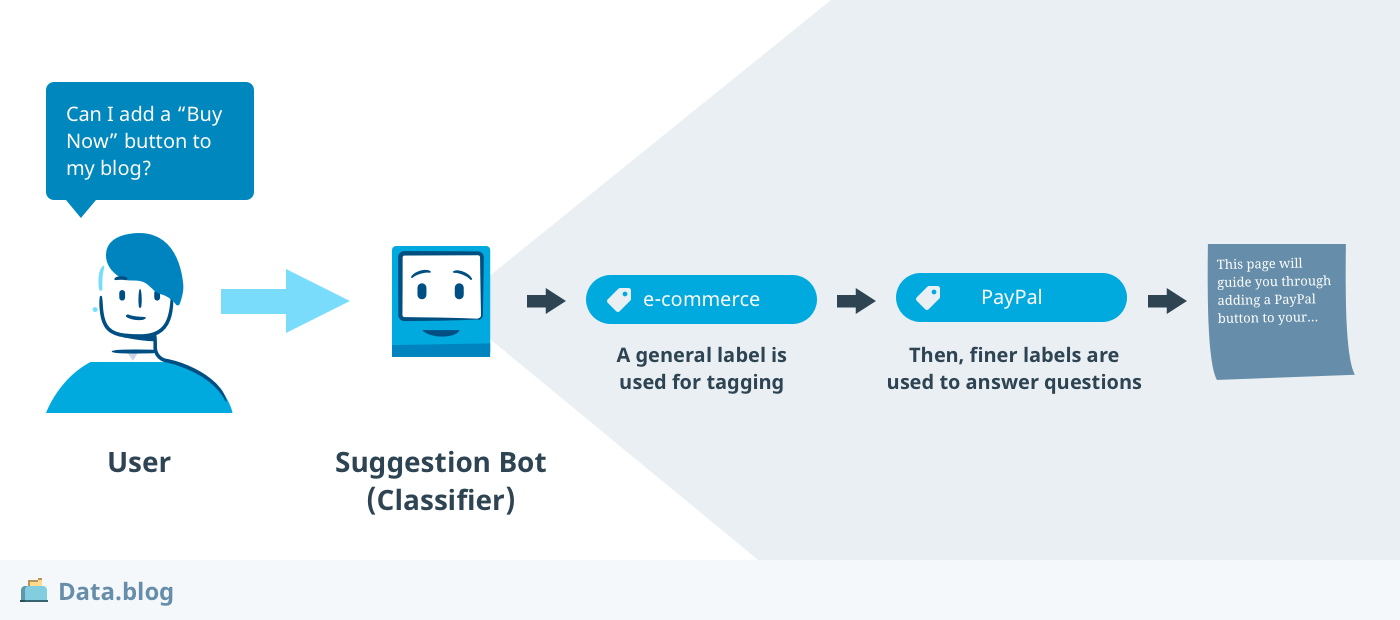
Using machine learning for classification
One approach to take in building the classifier here is to use machine learning — instead of specifying explicitly the rules for matching a question to a response, we use an algorithm that can discover the rules on its own.
Our initial hope was to use unsupervised machine learning for this task. Our chat metadata can include tags, but the tags themselves do not distinguish between chat topics at the response level. For example, we get many questions related to domains, and there are at least a dozen types of issues within this high level topic, and each requires a distinct approach to troubleshooting. However, the high level tag, domains, puts all of these issues into one group. Could an unsupervised learning algorithm discern these distinct subtopics on its own? We tried clustering based on chat features extracted using Latent Dirichlet allocation (LDA, [1]) and word2vec [2], but neither approach resulted in categories with enough granularity for questions and answers.
We began developing a classifier using supervised machine learning, but this required building a richer taxonomy of chat labels — labels that would map directly to concrete responses.
Where do the labels come from?
The key ingredient for supervised machine learning work is lots of labeled data for the algorithm to learn from. But we needed detailed labels at the specificity that would allow the labels to be linked to the appropriate answers. The first task was to develop this taxonomy.
Our taxonomy uses the question types encountered in day-to-day operations. The treemap diagram below depicts the main question types from that taxonomy.
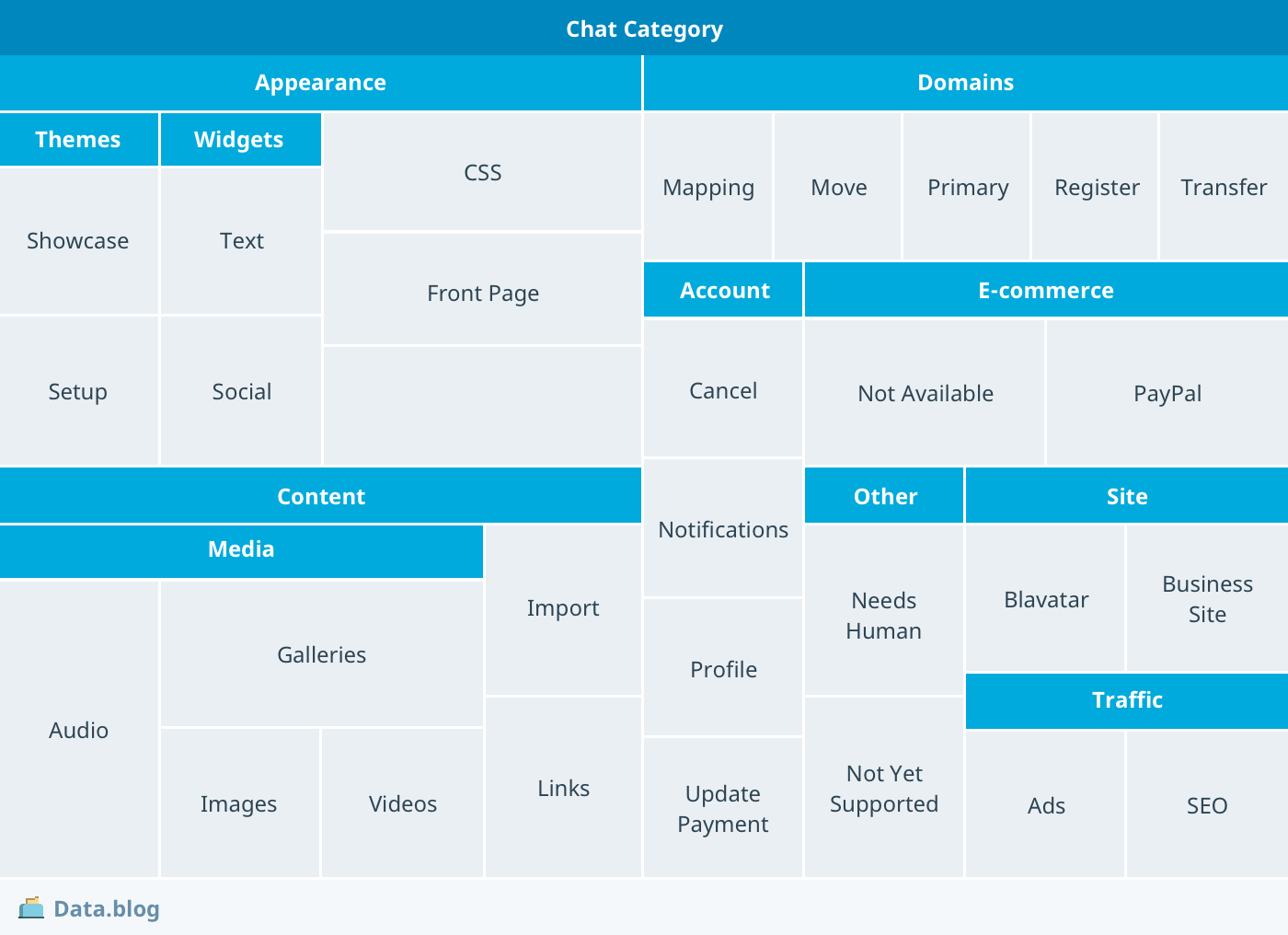
Questions related to site appearance and domain management figure prominently in the taxonomy. Present also is the e-commerce category in which we placed the PayPal question. There’s also a needs-human sub-category that represents questions on which the bot knows not to chime in. We realized that most of the chats fall into this category — a lot of the questions we address simply don’t have quick answers and require the human touch.
Having defined the taxonomy, we developed a web application that would allow HEs to assign labels to chats based on the taxonomy. That is, to link questions to the most appropriate answers, we needed to have the questions split into more precise categories than used for tagging. In collecting these labeled questions, we were also concerned about inter-rater reliability: we wanted the classifier to give answers that would agree with responses most HEs would give. We structured the labeling process so that each question and answer pair was labeled by at least two Happiness Engineers, and it was our original plan to train only on those cases for which we had consensus.
Building the classifier
The final taxonomy has 109 sub-categories, each paired with its own response. We used a vector space bag of words document model for the first iteration of our trainer. That is, we formed a vector representing each token using feature hashing [3] and used the count of the token in a given document to indicate its weight.
The algorithm we used initially was the One Against All (sometimes referred to as one-against-the-rest [4]) multi-class (OAA) classifier. Assuming that the number of categories is 
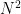
Preliminary results
We labeled a total of 2,702 chat questions, and of these there were 1,063 unique questions (providing for double annotation). To get a baseline measure of performance, we trained the OAA classifier chats with double annotation, for which annotations were in agreement.
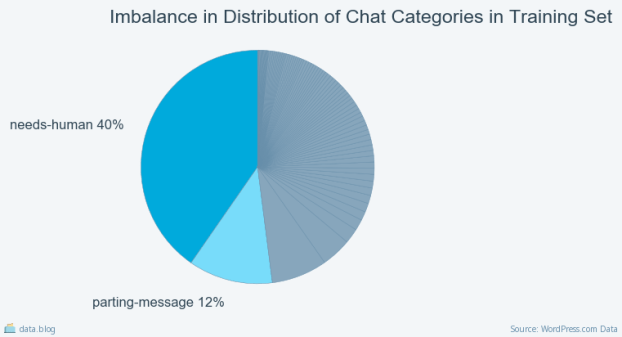
Of the 1,063 labeled questions 20% were set aside for validation and another 10% were set aside for testing. Even after several weeks of chat labeling, we faced the large challenge of an imbalanced data set. That is, a little over half of the labeled questions were in categories that aren’t helpful in assisting HEs — needs-human (the questions requiring deeper investigation) or parting-message — as shown below.
Looking at individual counts of examples for appearance and domains sub-categories highlights the imbalance issue.
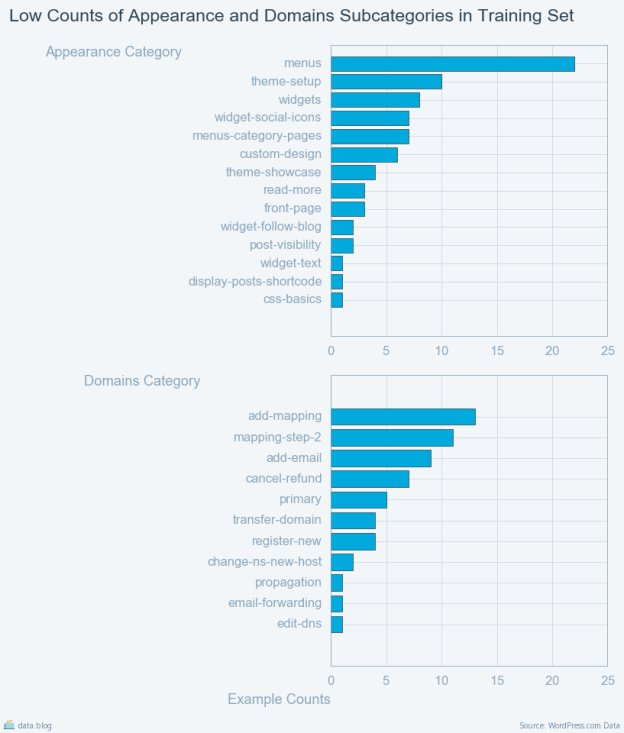
Most of the categories in this original analysis had too few representatives to train on and there were cases where a single instance of the category appeared in the training set and not in evaluation or test sets and vice versa.
Only 13 out of the 109 chat classes had representative samples in both training and test sets.
We therefore had to look into a number of ways to collect additional examples, without overly imposing on the HEs who had done the initial labeling. (Some of our findings could be useful for organizations trying to develop machine learning applications on limited data.)
Expanding the training set
The central problem facing us was data imbalance: a lot of examples of one kind (needs-human) of question but very few of the other kinds (domains:add-mapping). Broadly speaking, the approaches to this problem are to either make better use of the few examples that are available, or collect new ones.
We first attempted to label new data, but the task of identifying several thousand examples of sparse classes was challenging. The next choice was to identify a way to weight the examples so that the learning algorithm can pay more attention to the infrequently occurring cases, and less to those cases which occur frequently. This works for some classes better than others.
We also attempted to generate synthetic examples to address the imbalance. Again, this had impact on some cases more than others. We speculate it is because the cases we were attempting to model tend to be far apart in syntactic similarity. The most impact came from bootstrapping with nearest neighbor search and from the use of cross validation. These are described below.
Bootstrapping using semantic search
A third approach we tried was to identify new examples based on the unsupervised machine learning methods. In this approach, we turned to word embeddings to help identify candidate questions and responses to include in an expanded training set.
For this search, we used word embeddings constructed using Facebook’s fastText library [6]. FastText learns embeddings that predict successor and precursor characters allowing it to encode frequently used abbreviations and misspellings. These are abundant in chat questions. Using fastText we trained a 300 dimensional word vector model on our corpus of chat logs.
The search algorithms look through chat logs for those question and answer pairs for which the question is highly similar to a labeled question (i.e., the cosine similarity between the sentence vectors [7] is >= 0.9) and the answer contains the help URL associated with the labeled answer. These highly likely examples are then added to the training set. We were able to add 7,000 more examples to our training set and achieve a better balance of training examples using this approach.
Cross validation to make the most out of our set
Another approach useful for boosting the impact of smaller data sets is cross validation. Typically in the development of machine learning models, there are three distinct sets: train, validation, and test. It has been shown that you can effectively split the entire set into 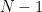
The cumulative effect
Combining these methods resulted in a dramatic improvement in the performance of our classifier as measured by F1 score. The comparison below shows the performance of the initial baseline against chats collected some months after the expanded training set. In this comparison the scores associated with the high level categories domains, appearance, and account are averaged across the scores for the respective subcategories.
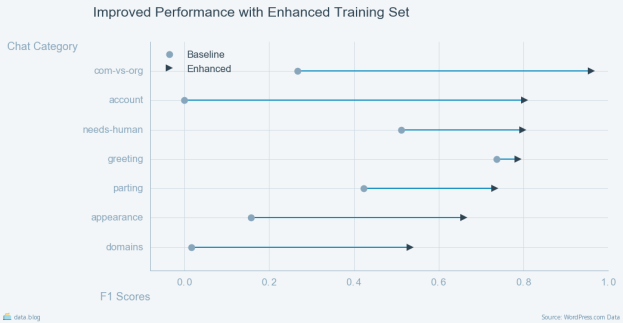
The scores are consistent with results reported for state of the art question answering systems [9] and we are looking into ways to improve performance across the domains category. There is significant improvement over the baseline model.
Conclusions
The main takeaway from our work on classifiers is that you can in fact derive a lot of value from using machine learning on smaller data sets. The other is that intermediate models — in our case the word embeddings constructed with fastText — can be used effectively to bootstrap larger sets for training.
We’re now in the process of putting the classifiers described here into production to support our Happiness Engineers. We are exploring whether neural network architectures — in particular recurrent neural networks [10] — can provide better performance than the OAA model.
References
1. D. Blei, A. Ng, and M. Jordan. “Latent Dirichlet allocation.” Journal of Machine Learning Research, 3:993–1022, January 2003. pdf
2. T Mikolov, I Sutskever, K Chen, GS Corrado, J Dean. “Distributed representations of words and phrases and their compositionality,” Advances in neural information processing systems, 3111-3119, 2013. pdf
3. K Weinberger, A Dasgupta, J Langford, A Smola, J Attenberg. “Feature hashing for large scale multitask learning,” Proceedings of the 26th Annual International Conference on Machine Learning, 2009. pdf
4. J Milgram, M Cheriet, R Sabourin. “‘One against one’ or ‘one against all’: Which one is better for handwriting recognition with SVMs?”, Tenth International Workshop on Frontiers in Handwriting Recognition. pdf
5. Agarwal, Alekh and Chapelle, Olivier and Dudik, Miroslav and Langford, John. A Reliable Effective Terascale Linear Learning System. 2011. Github repository
6. A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, Bag of Tricks for Efficient Text Classification. Github repository
7. Le, Quoc, and Tomas Mikolov. “Distributed representations of sentences and documents.” Proceedings of the 31st International Conference on Machine Learning (ICML-14). 2014. pdf
8. Avrum Blum, Adam Kalai and John Langford. “Beating the Hold-Out: Bounds for K-fold and Progressive Cross-Validation.” Proceedings of the 12th Annual Conference on Computational Learning Theory (COLT ’99), pp. 203–208. pdf
9. Wang, Shuohang, and Jing Jiang. “Machine comprehension using match-lstm and answer pointer.” arXiv preprint arXiv:1608.07905 (2016).
10. Jozefowicz, Rafal, Wojciech Zaremba, and Ilya Sutskever. “An empirical exploration of recurrent network architectures.” Proceedings of the 32nd International Conference on Machine Learning (ICML-15). 2015. pdf




Leave a comment