
“I will never stop learning” is the first line of our creed. To create learning opportunities, we’re inviting speakers to share their insights in our new Data Speaker Series. In the first installment in the series, Thorsten Dietzsch spoke to us on building data products at Zalando. Today, one of our own, Charles Earl, shares how to address bias in machine learning models. Enjoy!
For this month’s Data Speaker Series, I gave a talk — entitled Learning to be Fair — describing how gender, racial, and ethnic biases can creep into machine learning models as well as approaches to addressing these biases.
Making the web a better place
At Automattic, we are passionate about making the web a better place. We are currently looking at the role Artificial Intelligence (AI) and machine learning might play in achieving that goal.
Across the web, while machine learning has given us better tools for communication, knowledge discovery, and creative expression, there is by now a banality to the gender and racial bias apparent in so many AI systems. From predatory lending, to exclusionary facial recognition systems, to openly racist chat‑bots, discriminatory AI is a far cry from the “better place” that Automattic envisions.
With this talk, I hoped to jump start the conversation about how we can identify and build inclusive AI.
Discriminatory AI in the Wild
Bias shows up in four important application categories: search, machine vision, decision support, and natural language processing.
In 2013, Harvard researcher Latanya Sweeney noticed that Google searches for racially associated personal names would give higher ranking to ads suggesting criminal history. Sweeney’s publication lead to re‑examination of the ranking algorithms, but similarly biased search results remain: Google searches for “professional hairstyles” are more likely to return images of women with European features, while results for “unprofessional hairstyles” return images of African American and Latina women.
In facial recognition, the lack of gender, ethnic, and racial diversity in training and feature extraction leads to poor classification across diverse faces. In his 2012 dissertation Heterogeneous Face Recognition, Brandon Klare examined the accuracy of six facial recognition systems across gender, race, and ethnicity. Three were commercial systems, two were based on fixed computer vision algorithms, and one used machine learning. Each system performed significantly worse on female faces, even for the machine learning system retrained on female faces. Klare was able to improve the accuracy 1.5% on African American faces by training on an African American cohort. Klare attempted to improve performance on Hispanic faces but was not able to do so because of the limited size of the training set. The results show the impact of sampling bias, especially for the commercial systems, as well as feature selection bias: facial features used even in the machine learning system were skewed more toward male faces.
Although these results were from 2012, there are recent examples that point to persistent bias in machine vision. The computer vision startup Kairos claims that popular machine vision web services still practice exclusivity.
Decision support covers a vast array of applications — these services hit home when this involves informing (or making) the decision about who will get approved for credit, an account, or who remains incarcerated. The Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) system scores an offender for their risk of recidivism. COMPAS is used to make parole decisions in many places and has been the subject of several investigative reports. At issue again is how the learned model incorporates racial bias in its scoring.
Of particular importance to WordPress is the use of natural language processing (NLP). We are working on using NLP to build tools for our Happiness Engineers as well as other applications. Machine‑learned models for NLP have been shown to include both gender and racial bias.
Multiple Perspectives on Discriminatory AI
Here are some perspectives from which to view, and potentially mitigate the impact of these systems:
- As a technical debt. An influential paper by Google developers outlines how machine learning brings its own unique technical debt. Many of the mitigation strategies suggested by Google — especially in surfacing sample and latent biases — can be applied.
- As a inclusive design problem. Automattic has committed itself to developing design guidelines that promote inclusivity. Many of the guidelines — establishing diverse teams and choosing data with care — are useful.
- As a problem in algorithmic fairness. There is a growing body of work on de‑biasing algorithms based on standards of fairness — being able to trade off precision/recall and other metrics against the impact on a group of users. The field is just beginning to address important questions like being able to detect sources of inequality in data before an application is deployed.
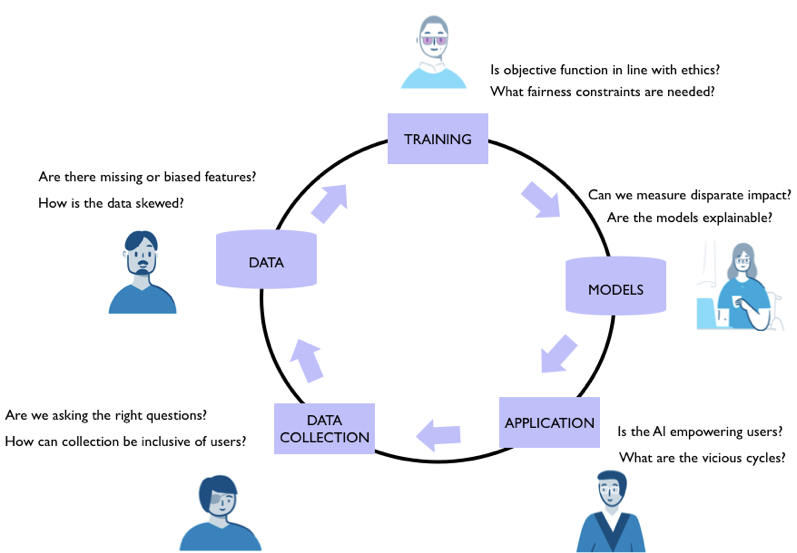
Some paths forward
Here are some paths forward based on integrating the perspectives into a complete lifecycle of AI system design.
Recommended reading
There were a few papers that I refer to in the talk:
- Quantifying and Reducing Stereotypes in Word Embeddings by Tolga Bolukbasi, Kai‑Wei Chang, James Zou, Venkatesh Saligrama, Adam Kalai.
- Equality of Opportunity in Supervised Learning by Moritz Hardt, Eric Price, Nathan Srebro.
- A remote conference on design and exclusion.




Leave a comment