
“Top Level Domain,” or TLD, is the “suffix” at the end of every domain name on the internet. The oldest and the most common TLDs are, .com, .org, and .net. Today, there are hundreds of TLDs available on the net, including .blog, which is almost one year old.
How do people choose the TLD for their domain name? Are there words people more closely associate with a .com TLD than with the .org? What about .blog, which is the second-most popular TLD registered with WordPress.com?
To answer these questions, we checked domain name mappings created between October 1, 2016 and October 1, 2017. The following figure shows the registration dynamics during the period. Note the registration peak in January. This is what we call the “New Year Effect” — a sudden increase in blogging activity possibly caused by the many New Year’s resolutions people make.

As one would expect, the .com TLD dominates our list with 68.4% of all mappings. The second-most popular TLD is .blog with 13.1%. The graph below shows the prevalence of the 10 most popular TLDs mapped with Automattic:

In this post, I will cover the four most prevalent TLDs: .com, .blog, .org, and .net. To analyze keyword affinity to the different TLDs, I used a dictionary-based word segmenter to split a domain name into its potential components. For example, using this segmenter, “beerlover” becomes [“beer”,“lover”]. Currently, the segmenter is based on English and is not aware of many proper names. Thus, segmenting my personal blog site, https://gorelik.net results in [“gore”,“lik”]. For the purpose of this analysis, dictionary-based segmentation is sufficient.
It is interesting to note that, among the popular TLDs, the one with the fewest components (tokens) is the newest one — .blog, which is represented by the blue line in the figure below. The .com TLD (black line) is so saturated, that people are forced to select longer, more complex domain names, evidenced by the higher peaks at the three, four, five, and six tokens per a domain name.

To compute the probability of TLD given a token 

where 


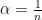
For easier computation using very small numbers, we compute the affinity score as follows:

Most discriminative token
Obviously, some keywords will not have a preference to any given TLD. One would expect to find very common words such as “the,” “and,” “of,” “a,” and others among such non-discriminative keywords. We excluded such words from our analysis. To identify the keywords that have a strong preference toward one of the top four TLDs (.com, .blog, .org, .net), I computed the mean absolute deviation of the 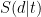

As we see, most of the preference variability happens in the .blog TLD. Thus, tokens most related to the .blog TLD are “site,” “that,” “com,” “faith,” “style,” “fashion,” “science,” “girl,” “its,” “adventures,” “code,” and “hope.”
Tokens less related to .blog are “lab,” “academy,” “services,” “solutions,” “inc,” “productions,” “llc,” “center,” “church,” and “blog.”
It is interesting to note the appearance of the “blog” token in the “non-blog” group. Maybe it’s about time to switch to the .blog domain?
Most discriminative TLD
Similarly to how different tokens can show different preference to different TLDs, some TLDs are more sensitive to keywords than others. To examine this aspect, I computed TLD-wise MAD values for all the tokens that appear in our dataset 100 times or more. I also extended the TLDs that I analyzed to other language-neutral domains: .com, .blog, .org, .net, and also .co, .live, .info, and .online. I did not include country specific domains, as those results are expected to be influenced by different language characteristics.

The figure above shows domain name discrimination, as measured by MAD values for the tested domains. The categories are sorted according to the TLD prevalence in the data set. On one hand, we can see that the “special” TLDs are much more sensitive to the keyword. On the other hand, the strong correlation between the TLD rank and the MAD value suggests that this apparent sensitivity is a result of different sample sizes — the more popular a TLD is, the more it is sensitive to extreme values, and the higher the computed MAD.
Remember that the results that you see here are descriptive. In other words, they don’t prescribe what name to choose for your site, they only describe the current situation, and give some food for thought. They also serve as a reminder that if you have a personal site but not a personal domain name, it is a good idea to register one with a TLD of your choice.




Leave a comment