
Over the past 18 months, the Decision Science team has been building the Experimentation Platform (ExPlat): a tool to help our colleagues run experiments to improve customer experiences, inform product decisions, and quantify the impact of newly released features on many of Automattic’s products such as WordPress.com, Jetpack, Akismet, and more.
In this multi‑part series, we will take you under the hood and share some of what we loved about building our new Experimentation Platform. This post is an overview of the platform and what’s on our project roadmap. Future posts will include deeper insights into our architecture, assignment system, and the open source UI called Abacus that we use for experiment management.
Why do we run experiments?
Many teams at Automattic want to measure how new ideas affect a user’s experience. Running an experiment provides the confidence and scientific rigor to quantify the effect across metrics important to our business such as new user signups, purchase conversions, and incremental revenue. Running experiments also allows data to inform and drive our decisions instead of the highest paid person’s opinion (HiPPO).
Comparing trends before and after a new feature is released can be a very manual, intensive process, and it can be difficult to attribute changes to a given feature because of confounding variables that may be influencing the results. These analyses usually have to account for things like seasonality, current events, and competing new releases from fellow colleagues.
This is where experimentation and the power of randomness comes to the rescue! A common experiment we run is called an A/B test where we randomly assign users to one of two user experiences: the `A` group receives the default user experience while the `B` group uses the newly designed feature.
Because users are randomly assigned to each group, the confounding variables have an equal chance of affecting both groups, which means the only difference between the two variants is the new feature we introduced to the `B` group. Any difference in metric performance can be attributed to the new feature. This is the subtle brilliance and simplicity of A/B tests!
The new experimentation platform
We’ve built our new experimentation system with many years of historical experiments in mind. Our new system is called ExPlat, and in order to accommodate many types of experiments (A/B tests, multivariate, geo/quasi experiments), we’ve broken up the initiative into five parts:
- Experiment education and review hub
- Experiment management UI
- Experiment client libraries
- Assignment system
- Analysis and metric ETL
The experiment education and review hub is the starting point for experimenters at Automattic to learn how to design and deploy an experiment. We have an internal blog (called a P2) for experimenters to get feedback on proposed experiments. We also have a wiki to share resources like a pre‑experiment checklist, how to write a hypothesis, and how to create metrics that capture a project’s intended impact. Experimenters can post their experiment design to discuss it with colleagues and ask for comments and reviews from our team.
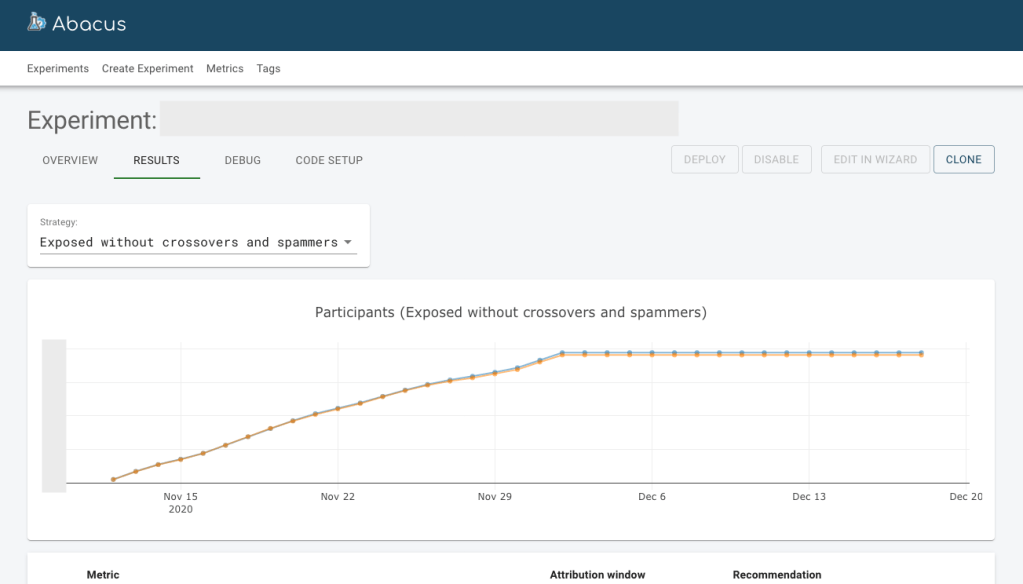
The experiment management UI is called Abacus and is an open source project. It is where experimenters go to set up, deploy, and analyze their experiments. Abacus allows everyone at Automattic to run and analyze their experiments, not just engineers and data scientists. The UI helps people schedule their experiments, visualize experiment results, and remotely start and end experiments.
Abacus is an open source project because we believe in democratizing experimentation the same way WordPress believes in democratizing publishing and the “freedoms that come with open source.” The experiment management UI is under the GPL license and is available for anyone to contribute and/or use in their own experimentation system!
Engineering teams can use the client experiment libraries when coding up the two variants of their A/B test. These client libraries simply consume the APIs that expose our assignment system and are built locally within a platform so that many different products within Automattic can run experiments.
Most experimenters will only use the experiment review hub, management UI, and the client libraries. By limiting experimenters to these three parts of the platform, we can help protect the integrity of experiments and create interfaces that make it easier to learn from experiments quickly and make it harder to commit time‑consuming mistakes.
The assignment system deterministically assigns users to an experiment group and takes into account the experiment model definitions in Abacus (eligibility, audience targeting, allocation ratios, etc). We offer two ways to assign users to experiments: real‑time assignment and batch assignment. Most of our A/B tests are real‑time assignments where users are assigned a test variation when they arrive at a specific experience in a product. Batch assignments are used for email experiments and machine‑learning marketing campaigns.
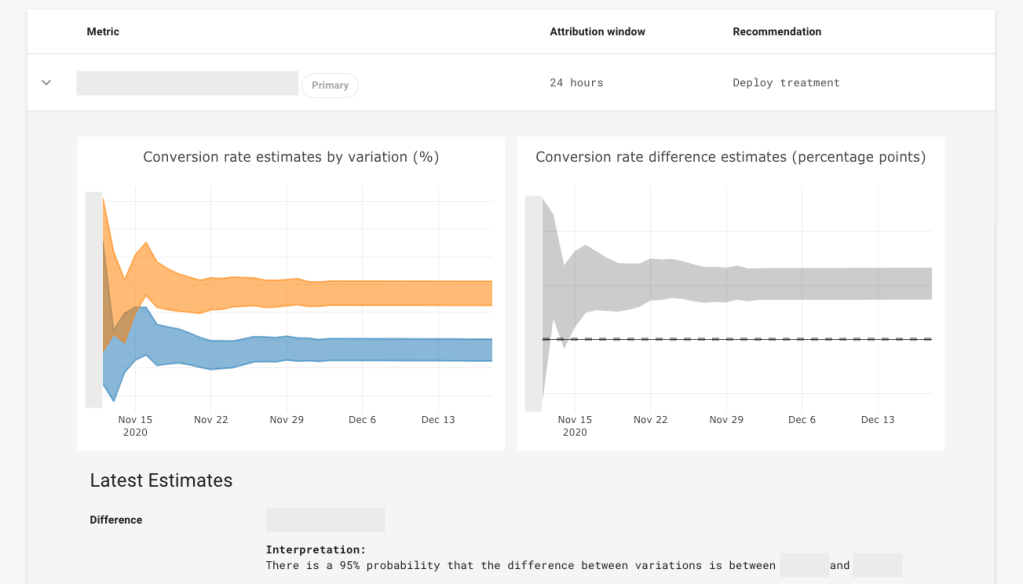
The analysis and metric ETL collects and processes performance metrics like conversion rates and average revenue per user for each running experiment. The experiment metric data is analyzed using Bayesian models to generate credible intervals. The analyzed experiment data is then visualized in Abacus where the experimenter can compare the performance of metrics across the experiment and decide which variation to deploy.
Experimenters conclude their experiment by sharing a summary comment on the experiment review hub about the results of their experiment. Each experiment contributes to a searchable repository of knowledge where we can share and learn from each other’s work.
What’s on our roadmap?
The future of experimentation at Automattic is very bright! We’ve released the new Experimentation Platform internally and one of our first major experiments was quantifying the influence of monthly paid plans where we observed a significant increase in paid purchase conversions. Many teams across Automattic have begun transitioning to the new Experimentation Platform, and we’re adding support for many more use cases and clients, including email campaigns, the WordPress Android and iOS apps, and Akismet.
In the near future, we hope to add new features like multivariate experiments and exclusive experiment groups. We also see opportunities to boost our education efforts and build a culture of experimentation by creating an experiment review guild: training and educating engineering partners to help design and review experiments. By democratizing the experiment review and education to teams, we can build local pockets of experiment culture across the company.
Stay tuned!
This is the first post in a series around Automattic’s new Experimentation Platform. We’ll have more members of the Decision Science team share their work on the different parts of the platform in future posts. If you’re interested in solving similar challenges, we’re hiring!
And if you’re interested in learning more about running experiments and building your own platform, we highly recommend the book Trustworthy Online Controlled Experiments by Ron Kohavi, Diane Tang, and Ya Xiu.




Leave a comment