
Last month, my colleague Aaron Yan published a broad overview of Automattic’s new Experimentation Platform (ExPlat). This month, we’ll dive deeper into ExPlat’s architecture and design, explain how the landscape at Automattic informed our architectural decisions, and describe the platform’s main components. Future posts will share details on each component and other aspects of experimentation at Automattic, so please subscribe to join us on this journey.
The pre‑ExPlat landscape
Architecting a software solution is similar to architecting physical structures: It requires an understanding of the landscape and how existing building blocks can be used to address stakeholder needs. At Automattic, our landscape includes the various systems that serve content to users and enable data analysis at scale, as well as a collection of existing solutions to A/B experimentation.
The main components of Automattic’s infrastructure relevant to ExPlat are:
- The WordPress.com production backend, which is written in PHP and backed by a collection of MariaDB instances managed by our Systems team. As MariaDB is a fork of MySQL, we’ll refer to the production databases as MySQL below. This component scales well and serves millions of users who host sites with us. It also powers other products in addition to WordPress.com, like Jetpack. As such, it is a mission-critical shared resource, and we must take care to ensure that deployed changes don’t degrade its performance.1
- Various front ends like static landing pages, the WordPress.com management UI (Calypso), and mobile apps that allow end users to consume content and manage their sites.
- The Hadoop-based data lake, which we use to run analyses and various ETL (extract-transform-load) workflows that are too costly to run on the end-user-facing backend. This component includes the Ganymedes system, which makes it easy for anyone at the company to deploy well-validated ETL workflows using SQL or Spark. When we started work on ExPlat, Ganymedes was still a new solution. Thanks to the great work of Automattic’s Data Engineering team, Ganymedes has evolved rapidly to address ExPlat’s needs and the needs of many other Automattic projects.
- Tracks, our home-grown user analytics solution. Tracks has clients in many of Automattic’s products that collect data and send it back to Hadoop via Kafka.
When we started working on ExPlat in late 2019, we had some A/B experimentation solutions at Automattic. Those solutions have helped inform our requirements for ExPlat, and their existence de‑risked the project: We were certain that we’d have enthusiastic experimenters, i.e., internal customers who want to run better experiments to inform their decisions.
In addition to experimenters, we also had some buy‑in from the business to support ExPlat in the long term. Our mission is to provide both the tools and the help needed to improve experimentation infrastructure and culture at Automattic. Even though some experimentation tools existed prior to ExPlat, they had no long‑term owners. As a result, experiments failed due to instrumentation issues, and wrong conclusions were drawn due to analysis bugs and tooling limitations. In short, the trustworthiness of experiments was too low.
The main A/B experimentation tools that we were aiming to replace with ExPlat were:
- The Calypso JavaScript abtest library, which enabled A/B experiments on the Calypso front end.
- The WordPress.com PHP abtest library, which enabled A/B experiments on the backend and static landing pages.
- The Hypotheses analysis tool, which supported limited analysis of A/B experiments run by the above libraries.
- Various other dashboards and ad-hoc analysis approaches.
Initially, we were hoping to gradually improve the existing tools, rather than embark on the daunting task of building a new system from scratch. However, a few factors led us toward building ExPlat as a new standalone project:
- While both the Calypso and WordPress.com libraries recorded events in Tracks, they were unaware of each other, meaning that A/B experiments that affected both the front end and the backend were hard to coordinate.
- Both libraries relied on hardcoded A/B experiment definitions, meaning that starting and stopping experiments required code changes. This led to some experiments running for years without a straightforward way to stop them automatically or even detect that they’re running.
- Hypotheses had improved the rigor of experiment analysis at Automattic, but it relied on bespoke Scala and PHP code that lacked adequate test coverage. With the Ganymedes solution (which didn’t exist when Hypotheses was implemented), it became much easier to run well-validated ETL workflows. Such validation is essential for implementing trustworthy experiments.
- Hypotheses required manual setup of a new analysis funnel for each metric, which led to inconsistent metric definitions and many avoidable human errors in experiment analysis. It also supported only conversion metrics, while many experimenters were interested in revenue metrics.
- Due to the lack of central ownership, all the existing tools had accrued long lists of known bugs and feature requests.
In summary, we pretty much had everything we needed: Systems that could support a scalable modern experimentation platform, a clear view of requirements by active experimenters, a set of tools to provide inspiration and improve on, and buy‑in from stakeholders to build ExPlat. With all of that in place, it was just a matter of architecting the system, building it, and taking experimentation at Automattic to the next level.
ExPlat’s main components and architecture
Our overall architecture is presented in the following diagram, where arrows roughly represent the flow of read/writes. For example, the uni‑directed path from MySQL to the Analysis UI means that the UI only reads the analysis tables, while the bi‑directed path from MySQL to the Management UI means that it also writes back to the production database.
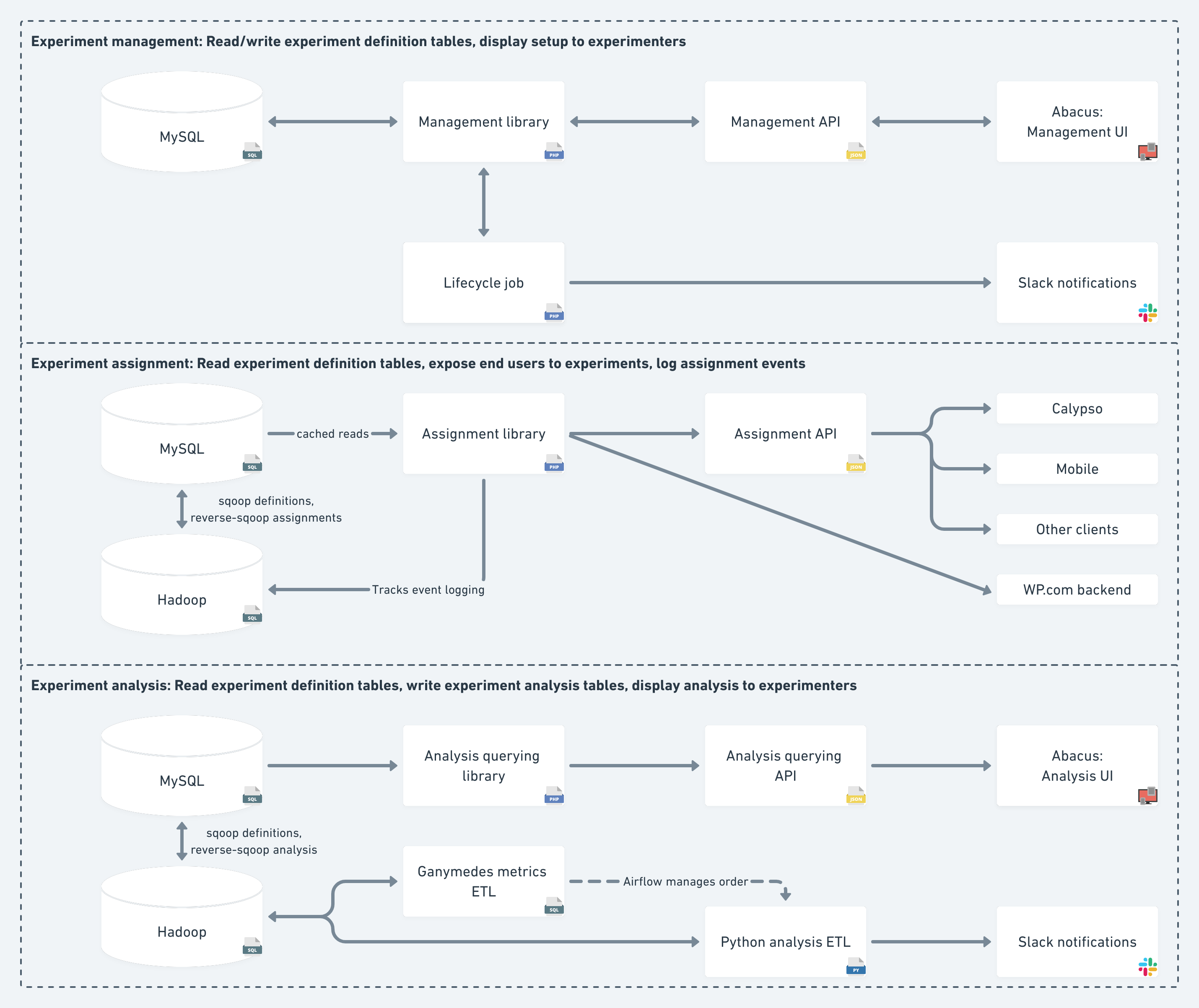
As the diagram shows, ExPlat can be broken up into three areas: management, assignment, and analysis. Each area has different operational requirements and responsibilities. All areas share some data through MySQL and Hadoop, but they are otherwise independent.
Experiment management comprises two parts: Manual changes by the experimenter to define and control an experiment, and automatic changes by the system as part of the experiment lifecycle. The former consists of fairly straightforward CRUD (create‑read‑update‑delete) operations on the experiment definition tables, with strict validations to ensure data integrity. The latter is done by a backend job that handles experiment status transitions and owner Slack notifications. Experimenters manage experiments using Abacus, our open source UI, which will be discussed in the next post.
Experiment assignment is the only area that interacts directly with end users. Its design will be covered in a separate post. The brief summary is that the assignment PHP library reads the experiment configuration from MySQL (via caches that reduce read load), but it doesn’t write to any MySQL tables. Instead, assignments are logged as Tracks events, and make their way to Hadoop and back to MySQL using a process we call reverse‑sqooping. Relying on Tracks for assignment logging improves scalability and makes it easier to control the write load on MySQL. Assignments are served to clients via the API, with the exception of the WordPress.com backend that gets the assignments directly from the PHP library.
Experiment analysis is done on top of Hadoop tables, as it requires Tracks data and specialized tools. This area includes our Ganymedes ETL jobs and a Python job, which employs Bayesian models to provide metric estimates and recommendations to experimenters. The analysis results are fed back to MySQL and displayed to experimenters on Abacus. We will share the details of our analysis approach in a future post.
Breakdown by component: Another way of looking at the system is by component/module. This roughly corresponds to the vertically‑aligned parts of the diagram. Specifically:
- MySQL tables are the source of truth for experiment definition and assignment.
- Hadoop tables are the source of truth for metric values and experiment analysis.
- PHP libraries are responsible for writing all the non-analysis MySQL tables. They also provide interfaces for querying these tables.
- The PHP libraries are accessed by non-PHP clients through APIs that correspond to the library functionality.
- The PHP backend job is responsible for managing the experiment lifecycle and sending lifecycle-related Slack notifications to the experiment owner.
- The Ganymedes and Python jobs are responsible for experiment analysis and sending analysis-related Slack notifications to the experiment owner.
- The Abacus UI is the only place experimenters need to access for experiment management and analysis, superseding all existing tools (hardcoded experiment configuration, Hypotheses, ad-hoc dashboards, spreadsheets, etc.).
- End-user clients (Calypso, mobile, etc.) are responsible for exposing end users to the experiment variations.
Join us!
Now that we’ve covered the architecture, we’re ready to go deeper into the implementation details of each component. These will be covered in posts over the coming months, so make sure you subscribe to get updates. And if you’re interested in working on ExPlat or other data projects, we’re hiring!
1 Anyone who’s developed code that gets deployed to WordPress.com is a bit wary of getting a “Barry Ping” — a short message by our Chief Systems Wrangler, Barry Abrahamson, notifying the person deploying the code that something somewhere went wrong. Despite this, we successfully deploy new code hundreds of times a week, and we love Barry. [back]
Cover photo by Lex Photography from Pexels.




Leave a comment