The metadata problem at scale
Automattic’s data ecosystem is large and highly interconnected: thousands of Iceberg tables and views queried via Trino, thousands of Airflow tasks producing and updating them via Spark jobs, and a growing catalogue of Looker and Superset dashboards and charts on top.
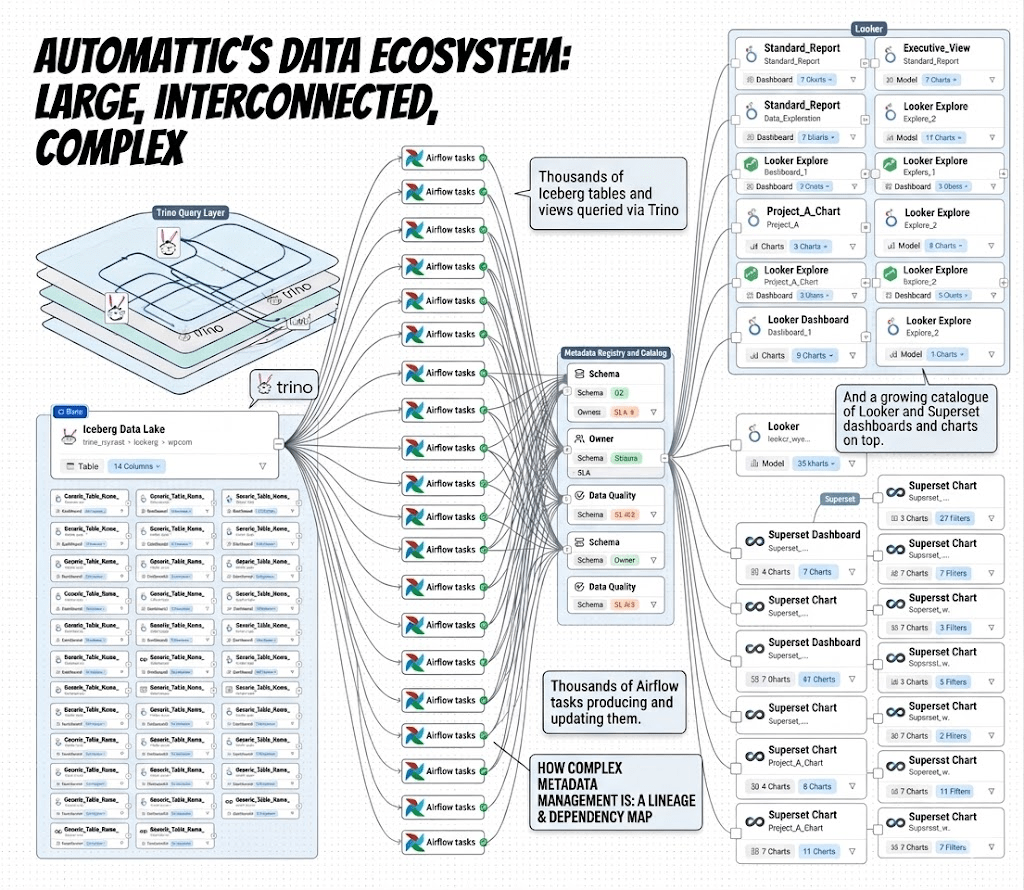
Most of the information about these assets exists somewhere, scattered across version control (like Git), schema registries (in some metastore like HiveMetastore), and the heads of whoever built the pipeline.
Anyone working with our data eventually hits the same wall:
- Which table should I query?
- Where did this data come from?
- Was it updated recently? When?
- Who owns this pipeline?
- Has this table grown recently, and was the latest run healthy?
These questions come up repeatedly. Answering even one usually requires knowing the right system to check, or the right person to ask. That doesn’t scale. It has become a bottleneck not just for humans, but also for the AI agents we increasingly want to put in front of our data.
We tried to address this with internal documentation pages describing our tables. They helped, but two gaps remained: people still struggled to find the right asset, and there was no lineage information. The most important question, “where does this data actually come from?”, kept going unanswered.
Why OpenMetadata
After surveying metadata solutions (where metadata is essentially “data about data”) and discovery solutions (DataHub, Marquez, Amundsen, Apache Atlas, Unity, ODD, OpenMetadata, and more), we picked OpenMetadata as the platform to consolidate everything: one user interface, one API, one graph that connects tables, dashboards, owners, profiles, quality checks, and lineage.
The platform is now live internally, and we are actively ingesting metadata from Trino, Airflow, Superset, and Looker.
What it gives us
A single source of truth for discovery
A centralized UI where anyone can find tables, dashboards, charts, and metrics; explore schemas and column‑level descriptions; browse ownership; check data quality results; and navigate relationships without needing to know where to look.
End-to-end lineage
Trace how a table was produced, which Airflow job ran, which upstream tables it depends on, and which dashboards consume it. Before changing a schema, you can assess downstream impact and understand the blast radius.
Data quality in the catalog
A database catalog is a centralized, self‑describing repository storing metadata about database objects such as tables, views, columns, users, and constraints. Quality tests check results live alongside the tables they validate, so users can confirm freshness and correctness without leaving the catalog.
Live profiling
Row counts and last‑updated timestamps are captured after each pipeline run, keeping the catalog in sync with the actual state of the data. This also helps answer questions like “how much has this table grown in the last 15 days?”
Auditing and change tracking
Schema, ownership, and annotation changes are versioned for debugging and compliance. Users can also be notified of schema updates, critical for catching issues that might break dashboards.
Why this matters for AI agents
OpenMetadata is not just for humans.
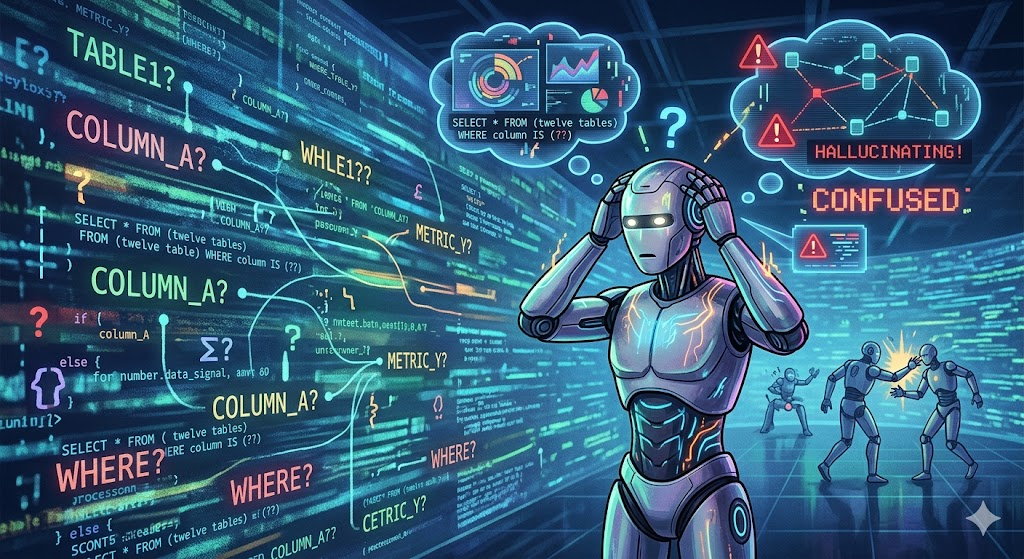
An AI agent querying Trino without metadata context produces unreliable results: it cannot know which of twelve similarly named tables is the authoritative one, whether a column is still maintained, or what a given metric actually represents. At scale, this becomes more than a discovery problem. It becomes an operational risk.
Increasingly, we want AI agents and automation systems to interact directly with our data platform: generate queries, investigate incidents, validate transformations, understand lineage, and reason about data quality. Without metadata, those systems are effectively blind and more prone to AI agent hallucinations.
The same context humans rely on, ownership, lineage, freshness, semantics, and quality signals, is also what allows agents to operate safely and intelligently on top of a modern data platform.
With a rich metadata graph in place—table descriptions, column semantics, lineage, ownership, and quality results—agents can make the same informed decisions as a data engineer.
A few concrete things a metadata‑aware agent can do that a blind agent cannot:
- Resolve ambiguous table references by checking descriptions, ownership, and lineage before writing a query.
- Warn before suggesting a transformation that would break a downstream dashboard by walking the lineage graph first.
- Surface data quality failures as context (e.g., “this table failed a column check 3 days ago”), and, if the agent has access to the repository and understands the pipeline, even fix the issue.
- Identify the right owner to contact when a table needs to be dropped or its schema changed.
We are currently testing an MCP server that exposes OpenMetadata to AI agents, allowing them to search assets, fetch schemas, navigate lineage, and retrieve quality results, with semantic search for more precise answers.
Semantic search in OpenMetadata currently only works with OpenSearch. Since we run Elasticsearch, we are contributing the Elasticsearch implementation upstream so the same capability works on both backends.
How we keep the catalog fresh
Two complementary ingestion paths feed OpenMetadata, keeping the catalog continuously up to date:
- Async (DAG‑based)
An Airflow DAG (openmetadata_ingestion) crawls Trino, Airflow, Superset, and Looker on a schedule. Each source runs as a YARN task (isolated) via a reusable OpenMetadataWorkflowOperator, using the official openmetadata‑ingestion library. This keeps the broader catalog up to date without coupling ingestion to individual pipeline runs. - Sync (per‑run)
An OpenMetadataSync module integrated into the Spark task execution lifecycle posts metadata updates after every job: table schema, column descriptions, ownership, lineage, row counts from the Iceberg snapshot, and the results of any data quality checks.
High-value, frequently updated tables stay continuously fresh without waiting for the next scheduled crawl (which still captures deleted and static tables).
Where out‑of‑the‑box connectors fall short, particularly for lineage edges they cannot infer, we close the gap with custom integrations using the OpenMetadata API directly. We also noticed that some Looker and Superset lineage and ownership mappings do not work as expected and require additional development.
Where we are, and what’s next
The OpenMetadata infrastructure and async ingestion DAG were recently deployed in our internal system. Even in its early stages, the catalog is already indexing tens of thousands of data assets across our analytics ecosystem, including Looker, Trino, Superset, and Airflow.
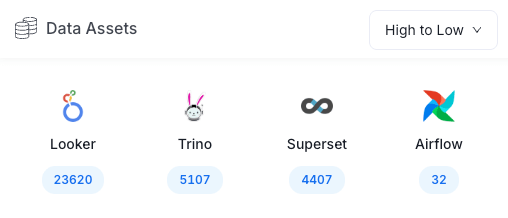
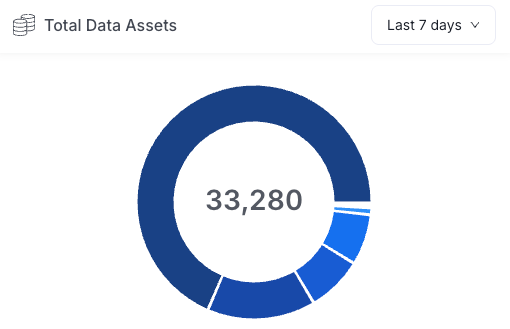
The remaining work falls into a few areas:
- Sync ingestion of per‑run metadata from Spark jobs.
- Ownership and lineage enrichment for Superset and Looker.
- Column‑level lineage via the OpenLineage Spark connector.
- MCP and agent integration to fully connect the catalog with AI workflows.
We have also started contributing fixes and improvements back to the OpenMetadata open‑source project.
If you build on top of Automattic’s data, whether as a human being or an agent, this is the layer that should make every next answer faster, safer, and easier to find.




Leave a comment