
We get asked periodically about how extensively we are using Elasticsearch. And it has come up twice in the past week, so time to write a blog post.
We are constantly expanding what we are using Elasticsearch for and so although some previous posts have broadly define what we are doing, they don’t really capture the continually expanding scale.
So here are some quick bullet points about what we currently have deployed:
- Five clusters with a mix of versions:
- 42 data nodes spread across 3 US data centers running ES 1.3.4. This cluster mostly runs related posts queries. 1925 shards. 11B docs. 43TB of data. 60m queries/day. 12m index ops/day (has been as high as 940m in a day though). Each index is 175 shards and has 10m blogs in it. Each blog is routed to a single shard so almost all queries only hit one shard, but we can (and do) search across multiple shards for some use cases.
- 6 data nodes across 3 DCs running ES 1.3.9. Hosts our WordPress.com VIP indices and lots of other use cases. 321 indices (mostly VIPs). ~8m queries/day. ~1.5m index ops/day. Typical VIP index config is a single shard that is replicated across the three data centers. Most of these indices are small enough that sharding would reduce performance and reduce query relevancy.
- 12 data nodes across 3 DCs running ES 1.7.5. Primarily powers search.wordpress.com. Indexes the past 6 quarters of all posts. One index per quarter with 30 shards per quarter. Queries typically hit all 180 shards.
- 3 data nodes across 3 DCs running ES 2.3.1. Currently an experimental cluster as we work to migrate to 2.x. Only production index right now is for en.support.wordpress.com.
- 15 (and possibly expanding to 100) data nodes for a Logstash cluster running ES 2.3. A lot of logging use cases for many different services. Growing rapidly.
- All of our clusters use three dedicated master nodes with one master in each data center. The first cluster has its own master nodes. The next three share master servers with multiple instances of ES running on each server.
- Typical data server config:
- 96GB RAM with 31GB for ES heap. Remaining gets used for file system caching
- 1‑3 TB of SSD per server. In our testing SSDs are very worthwhile.
- Query speed:
- Related Posts: median 44ms; 95th percentile: 190ms; 99th percentile: 650ms. This is way lower than when we launched in 2013 and 99th percentile was 1.7 seconds.
- VIP Queries: median: 25ms; 95th percentile: 109ms; 99th percentile: 311ms
- search.wordpress.com queries: median: 130ms; 95th percentile: 250ms; 99th percentile: 260ms
- Client-side Optimizations:
- We cache all queries results in memcache which cuts our ES query rate in half
- memcache timeouts vary from 30 seconds to 36 hours depending on use case
- We analyze all queries on the client side and optimize the ES filters:
- have a blacklist of fields that we never cache (blog_id, post_id, author_id) because they have such high cardinality (100m+ unique ids)
- we rewrite and/or/not filters into bool queries and try to flatten them into a single filter
- We don’t allow some types of queries (we have a whitelist)
- We don’t allow facets/aggregations on certain fields (content, title, excerpt)
- We generally don’t allow paging too deep or returning thousands of results at once
- A general pattern we use is to use ES to get IDs for content, and then we get the real content from MySQL for displaying to users. This reduces what data ES needs (we strip out HTML), and we can be certain the data is not out of date since ES can be up to 60 seconds out of date in some cases (though typically is less than 5 seconds).
- Query Use Cases (in order of query frequency):
- Related Posts
- Replacing WP_Query calls by converting slow SQL calls to an ES query (WordPress tag/category pages, home pages, etc)
- search.wordpress.com
- Language Detection using ES langdetect plugin (used for every post we index)
- Analyze API (used to perform reliable word counting regardless of language – in conjunction with the langdetect call)
- Blog Search (replacing the built in WordPress site search)
- Theme Search
- Search Queries that are used when reindexing content (eg when a blog’s tag is renamed we need to search for all posts with that tag and reindex them)
- Various support searches
- A number of custom VIP use cases
- A number of custom internal use cases (searching our p2s, suggesting posts that may be relevant to read, searching our internal docs, etc)
- Calypso /posts and /pages for getting/searching all posts a user has authored across all their blogs (potentially hundreds)
- ES Plugins Deployed:
Since images are always fun, here are our Graphana dashboards for our largest cluster over the past 6 hours. The first is our client‑side tracking of query/indexing/etc speed
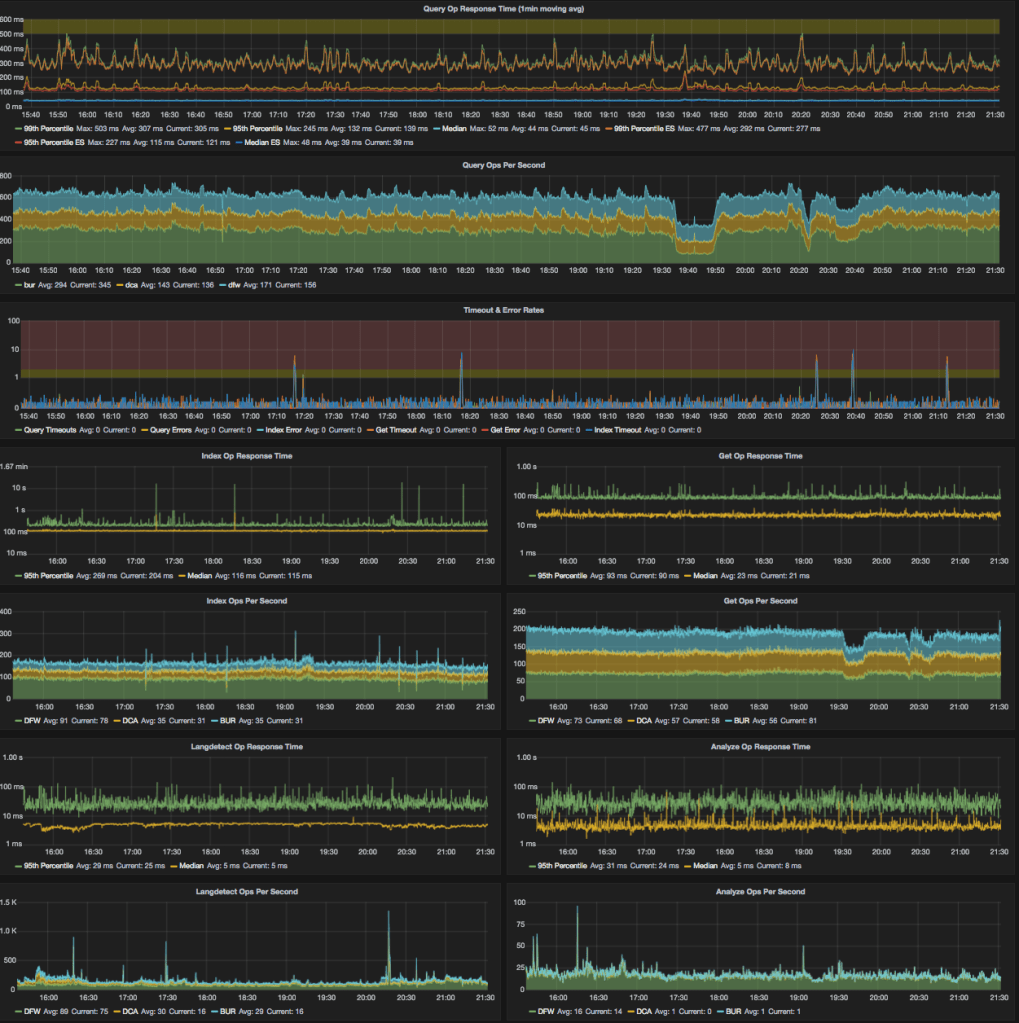
Second is our aggregated stats (from the StatsD plugin) about the cluster’s performance:
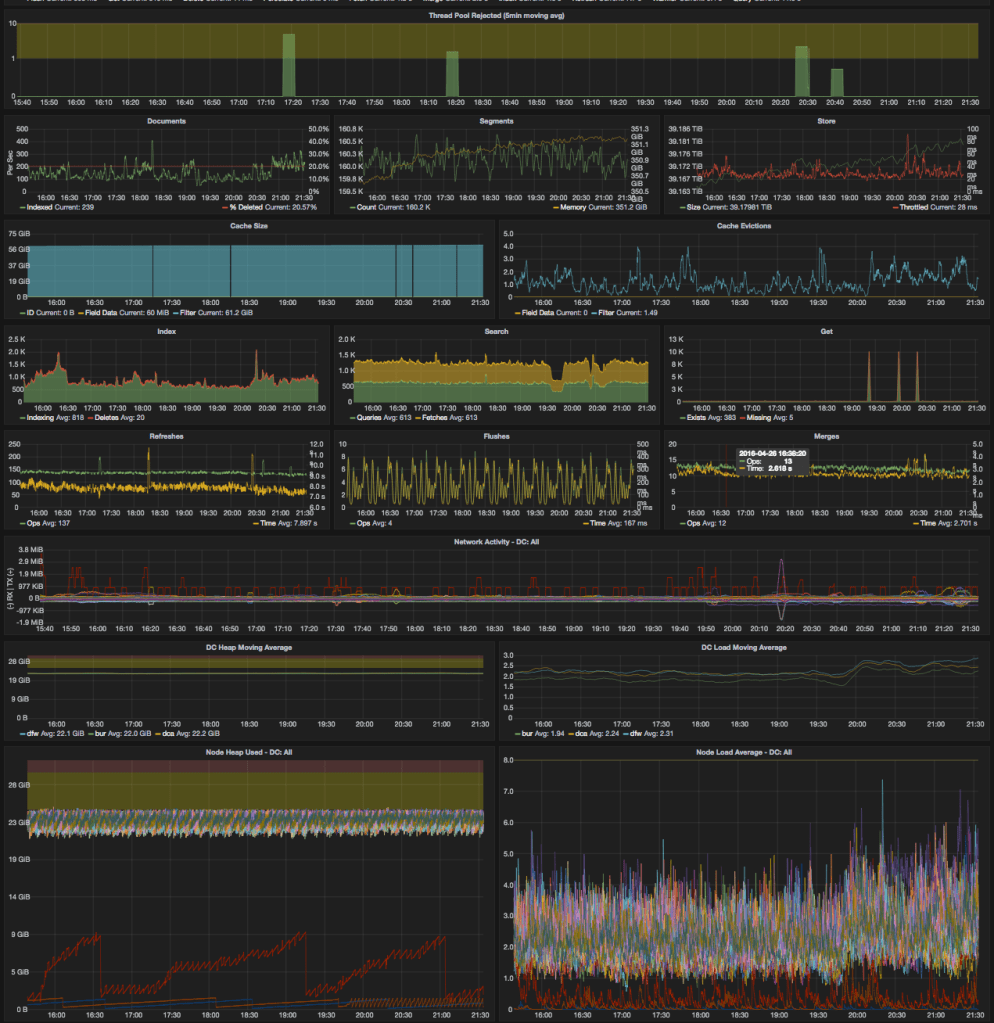
This cluster/index has been really solid for us over the past two years since it was last built. We have some known issues that have us stuck on 1.3.4, but we’ve also had times where the cluster went many months without any incidents. In general the incidents we have seen have been caused by external factors (usually over indexing or some other growth in the data).
This post was originally published on developer.wordpress.com.




Leave a comment