
WordPress.com is home to hundreds of millions of sites, a place to produce and discover content. Logging in, you’re automatically taken to the Reader, where you’ll find a stream of posts from sites you follow or that we’ve recommended for you. You can like, reblog, or comment on these posts. If you’re inspired, you can choose to publish a new post yourself.
Any time you take one of these actions, you become a part of an ever-shifting network. This network is what makes a WordPress.com site inherently different from a stand-alone site, and understanding networks is key to understanding the WordPress.com experience. In order to better understand what our users are reading and what kind of content they are producing, so that we can create tools and features that help them meet their goals, we set out to make this invisible network visible — to look at the communities of users, sites and posts within WordPress.com.
Community, in this sense, is a network science concept that denotes those entities within the WordPress.com ecosystem that have strong ties to each other. There are several ways to visualize the different communities within WordPress.com, since a community can be formed of blogs, users, posts, or a combination all of the above. Here, I looked at blogs to see which ones are connected to each other, how many communities they form in total, and how these communities can be characterized.
Let’s say you are a WordPress.com user and enjoy this post so much that you press the “like” button after reading it (consider that a subtle hint). Now we know that you have enjoyed content served on data.blog — it gives us a tie that connects you to data.blog. As you like more posts here, the tie grows stronger. You then move to another WordPress.com site, moredata.blog (which doesn’t exist… yet!) and like a post there. We now have another explicit action, a show of preference, that connects you to another site in the WordPress.com ecosystem.
We also now have implicit information, an invisible tie that can now be made visible: data.blog and moredata.blog have a connection, because they both have been liked by you. While this tie isn’t visible, we can uncover it by analyzing the actions of our users. If another user, who is also interested in data.blog and moredata.blog, ends up finding a third site — say, evenmoredata.blog — we can say that those blogs are similar, define even more ties, and start building a network and identifying communities.

The Various Topics on WP.com
Building, projecting, rigorous filtering, and clustering the user-blog network gave us a subset of the WP.com ecosystem with 109,099 unique blogs that belong in 428 distinct communities (an upcoming post will describe the methodology behind these steps). A few of these communities contain many blogs, and most of my analysis focuses on the largest communities with the greatest number of blogs — 15 communities in total. To better characterize these communities, I picked the top 1,000 most-liked posts from each one.
And now for the most exciting question of all — what kind of content are our users producing and reading? Are users searching for and consuming content based on particular topics? The short answer: yes! The top 15 communities’ most liked posts’ tag clouds are all very specifically centered around topics and themes. Blogs with distinct topics seem to cluster together — i.e., are liked by similar people.
Here are the top 15 English-language communities of WordPress.com from the past 45 days:

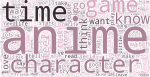
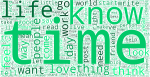







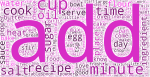
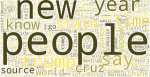



Most of them are distinct, but there are multiple communities around writing; some are general and don’t seem too different from one another, whereas others seem to have a particular focus like motherhood or blogging.
I also looked at some random clusters that were smaller and found very distinct topics there, like a community centered around self-driving cars. These should be taken with a grain of salt; since they were chosen randomly, some of these communities might contain only a very few blogs and posts:



Cluster Dynamics (and Controversy!)
Posts in clusters behave differently, and looking at likes, comments, and reblogs demonstrates these dynamics. For each blog, I calculated an average number of likes, comments, and reblogs, then took the mean of these averages for each cluster. In the figure below, we can see the mean of the average number of likes, comments, and reblogs that the blogs belonging to a given cluster receive.
I highlighted some of the more interesting figures in bold, such as highly likable communities around writing and photography. But the most interesting part is in dark blue: a community where the blogs receive more comments than likes. This is very unusual; since liking is a micro-action, one that takes minimal effort, it is used more widely than commenting. Usually, comments exceed micro-actions when a topic is controversial and the platform only allows positive micro-actions (e.g., likes or upvotes) and no negative ones.
SPOILER ALERT: It’s the politics cluster! This is the moment that made me throw my arms up in the air and exclaim, “It actually worked!” Not only do our users congregate into demonstrable, topical communities, but we can also these communities’ differing dynamics.

Community Distances
A blog can only belong to one community. But since blogs also have ties to blogs from other communities, we can look at a network of communities to see how well-connected the different clusters are. If a blog from one community has a tie with a blog from another community, then we define a relationship between these two communities. The stronger the relationship, the thicker the edge.
If you generally like posts from photography sites as well as posts from data-themed sites, then you are defining a tie between the photography and data clusters.

We see that photography is connected to almost everything — it’s at the center of the WordPress.com ecosystem. Matt started WordPress as a way to organize and showcase his photography, so it looks like we are sticking to our roots!
One of the advantages of using network science to analyze similarity — as opposed to text-based methods — is that we get to identify non-text based communities like photography. The graph visualization also tells us that while their topics might look similar, some of the writing communities are actually pretty distinct from each other.
These communities can now be used in various ways to power recommendations and understand our users and their sites better:
- We can identify top sites per cluster to help our Editorial team discover popular posts from a wide variety of communities.
- It allows us to define distances between communities – e.g., the makeup cluster is a short distance from the fashion cluster.
- Community-based characterization serves as a poor man’s topic modeling; we can tell what topic a blog might cover by just looking at the community it belongs to. We can do this even when the blog doesn’t have any actual text — e.g., a photography blog.
- It helps us characterize users based on which clusters they interact with, so we can recommend sites from the same cluster to them — if you liked this post, we can recommend additional posts to you from the data cluster.
There are many more ways we can analyze these clusters to uncover how they are different or similar, so stay tuned for more analyses on the communities of WordPress.com!




Leave a comment