

A generalized machine learning pipeline, pipe serves the entire company and helps Automatticians seamlessly build and deploy machine learning models to predict the likelihood that a given event may occur, e.g., installing a plugin, purchasing a plan, or churning.
A team effort, pipe provides general, long-term, and robust solutions to common or important problems our product and marketing teams face. When I first joined Automattic almost exactly three years ago, my tasks were two-fold:
- I had the autonomy and freedom to delve deep into topics of my choice, which at the time revolved around uncovering the networks hiding within our communities using network science.
- But like most data scientists in the industry, most of my time was spent serving product and marketing teams by providing answers to their data questions which ranged from running simple SQL-like queries to doing more in-depth — but one-off — statistical analyses.
We soon realized that while serving product and marketing teams must remain one of our main goals, we would be better off providing and maintaining general solutions.
We experimented with embedding a data scientist on a team for three months, so that we would work more closely with teams that can benefit from data products and provide longer-term solutions instead of one-off analyses or models. And this is how pipe was born.
Data science meets Marketing: first steps
My data science-marketing stint started with a a list of questions from Customer Marketing. The Customer Marketing team is responsible for our email campaigns, and they wanted to make their email campaigns more efficient. They wanted to find out which of their users could do without the Day 30 email that everyone received, so I started to tackle the following question:
Which free Day 30 users will upgrade to a paid plan by Day 44?
Since all Day 30 users receive this email, we could build a free-to-paid model that tells us which users act on it in order to only target similar users instead of everyone.
It took about three months to build the first pipeline that:
- Gets eligible users on a daily basis.
- Scores their likelihood to buy a plan based on pre-built models.
- Stores these likelihoods in a Hadoop table.
- Puts the users in buckets for A/B tests.
- Evaluates model performance on a daily basis.
- Identifies important features that contribute to the likelihood score.
- Generalizes this question to achieve the same flow for any Day N cohort. (Which Day 15/20/90…etc. users will buy a plan in the next 7/10/20…etc. days?)
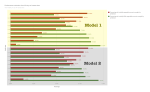
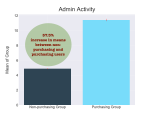
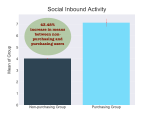
Most of the development time was spent on building the pipeline for generating, cleaning, and transforming the data and running the flow on a daily basis. The traditional “data science” work took only about one week of the three-month rotation as the data and software engineering issues had to be tackled first.
We ran a bayesian A/B test for an email campaign for Day 38 users to see if the model was actually selecting the users most likely to upgrade and found that it performed well enough. Those that the model selected as likely to buy a plan purchased plans at ~350% higher rate as a response to the email than a random selection of users.
Problems with the free-to-paid project
The 350% higher conversion rate as a result of an A/B test sounds like a marketer’s dream, so the project at a first glance was successful. However, there were many issues:
- We only proved that the model performs well and is able to select users who will upgrade, but it does not select users that upgrade due to our marketing efforts. These users may have upgraded with or without our email since we scored them only on their likelihood to buy a plan.
- While the conversion rate in the test group was high, the raw conversion numbers did not point to as high an impact. So the number reported for the increase in rate was not so important.
- We had technical issues with the robustness of the flow that needed data engineering help.
- We realized that raw likelihood scores may be more useful if they were about churn rather than likelihood to buy a plan.
So the question now became:
Can we generalize this flow and make it more robust so that we can quickly pivot in situations like these?
Since the answer was “yes, we can, but we need more time and resources,” the effort became its own project under a new team. My colleague Yanir Seroussi joined me. We named the project pipe — inspired by a wave that neither of us will ever get to surf 🙂
What pipe does
pipe builds machine learning models based on a site’s likelihood to perform any event that we track. These events can include a site publishing a post or a page, installing a plugin, or activating a theme. Once the event we want to build models for is specified in the command line interface, along with a unique project name, the cohort of the sites we are interested in (e.g., a free Day 30 cohort would be free sites that registered 30 days ago), and a conversion window, pipe will automatically:
- Generate training data labels for eligible sites.
- Generate features for these sites.
- Build a predictive model on the fly and save some information about model performance metrics and feature importances.
- Deploy the model and flow to our Hadoop clusters.
- Start generating daily likelihood scores using the model for new eligible sites and save them in a Hadoop table.
- Generate daily offline evaluations of model performance for sites that have reached the end of their conversion window and save these in a Hadoop table.
- Put sites into A/B test groups on a daily basis based on their likelihood scores. These A/B test group assignments for each site owner are also saved in a separate Hadoop table and can be used to run experiments to evaluate the model.

Example questions pipe can automatically build models for:
- Which free Day 15 sites will purchase a plan by Day 30?
- Which free Day 30 sites will purchase a plan by Day 37?
- Which paid Day 60 sites will churn by Day 90?
- Which paid Day 60 sites will fail to renew by end of their first year?
- Which free or paid sites that registered seven days ago will use the mobile app in the next 10 days?
- Which sites that became paid 30 days ago will install the simple payments button in the next 15 days?
Posts coming up
There will be a series of posts published on data.blog about pipe in the coming months:
- How
pipedoes what it does: a more in-depth look intopipeoutputs and howpipegenerates features, builds models, and does offline evaluations. - Using predictive models in Marketing: experiment setups for online evaluation; uplift modeling; building models that are useful as opposed to just accurate.
- Gotchas in machine learning: what to look out for when building machine learning models, and a discussion of common mistakes.




Leave a comment