
Welcome to the second post in our “Intro to Search”-series! Today, we’ll dig into the building blocks of search engines to give you an idea of just how we identify what posts to show readers using WordPress.com’s search tool.
A (web) search engine connects users with relevant documents. This process generally has five main stages:
Document collection: Any search engine needs to gather the collection of documents to operate on. A document can be a website, a scientific paper, a medical record, or a blog post on WordPress.com. Search engines collect these documents either by crawling the web, or directly at the time when a new document is created. The place where they are collected is called a document store.
Indexing: Among other signals for relevance and importance, search engines use word or term counts. The basic idea is that documents are only relevant to terms that are mentioned in them, and that the more often a word is used in a document, the more important it is in that document. Counting words in a single document is easy, but counting billions of words takes a ton of time. Counting only once and storing the results is much more efficient than counting every time a user searches for something. This storing of term occurrences for each document is called indexing. As part of this process, the indexer may analyze the text to stem words and omit the most common ones. Indexing may condense “All four species of giraffes have long necks and all giraffes are awesome.” into
four 1
species 1
giraffe 2
long 1
neck 1
awesome 1
by dividing the sentence into words (tokenizing), mapping words to their roots (stemming), counting, and removing the common words “all,” “of,” “have,” “and,” and “are.”
Query Building: Whatever a user enters into the search box has to be translated into a query that can be run against the document collection. If words are stemmed as part of the indexing process, we have to stem the terms in the search query, too. If very common words are removed before indexing, like in the giraffe example, we have to remove them from the query as well. Queries may or may not take the order of words into account, and they can include synonymous words or allow wildcards.
Ranking: Once a set of matching documents have been identified, they have to be put in the best order for presentation. To maximize users’ happiness, we have to show the most relevant, novel, and engaging posts at the top of the list. We’ve covered users’ expectations in the previous post in this series. There are various well-known ranking algorithms and machine learning solutions for this problem, and we’ll introduce some of the most important ones later in this post.
Presentation: Finally, a great search engine needs a clear and clean user interface. Ideally, it makes the search results look inviting while also presenting the user with all the information they need to decide which result to pursue.
Post search in the WordPress.com Reader
WordPress.com is home to many publishers, and we continuously integrate the tens of millions of posts they write every month into our searchable document collection. For fast and parallel document access, scalability, and convenient full-text search methods, we use Elasticsearch. We use Elasticsearch’s built-in indexing methods to make our users’ content searchable, and rely on its own query language to retrieve the right documents for each search. Our largest Elasticsearch cluster has 45 nodes and handles about 35 million queries every day, with a median query time of 130 ms for post searches.
Ranking functions and algorithms
For a data scientist like me, the most exciting task of a search engine is the ranking. The ranking of a document can be based on term frequency as a proxy for relevance, or on the importance of a document in a network of documents. It can also take several other signs of social validation or text quality into account.
BM25: This family of ranking functions [1] is a popular choice for measuring relevance. Each document is regarded as a bag of words, and its relevance with respect to a search term is measured by the term’s frequency in the document in comparison to the term’s frequency across the document collection. The length of the document is taken into account as well, and two tunable parameters control the growth of a document’s ranking as a function of the term frequency.
Compared to the collection of posts on WordPress.com, the slogan “Data for Breakfast – Ideas and Insights from the Data team at Automattic,” has a high BM25 score for the term “data” because it appears twice in the text and is not very frequent in our document collection, and it also has a high score for the less frequent term “Automattic.” Contrary to this, a word like “idea” is fairly common and the slogan doesn’t have a very high BM25 score for this term.
The BM25 score for a document 

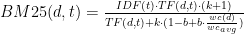
Here, 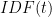
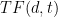

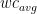


In contrast to a simple 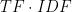
 appears in the document . The scores are normalized to their value at
appears in the document . The scores are normalized to their value at 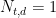 . The document in this example has a total length of 500 words, so at
. The document in this example has a total length of 500 words, so at  , we would have a document that consists of only one word, repeated 500 times.
, we would have a document that consists of only one word, repeated 500 times.
PageRank Probably the most famous of all ranking algorithms, PageRank [2] was published by Google founders Sergey Brin and Larry Page. PageRank is a recursive algorithm that ranks web pages by a weighted sum of incoming links; an incoming link from a page with high PageRank and few outgoing links counts the most. The PageRank 
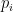
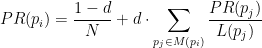
where 

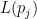

PageRank isn’t applied only to web pages but can also be used to rank scientific papers or nodes in any network.
HITS: Hyperlink-Induced Topic Search is another recursive algorithm, and its goal is to find two particularly interesting types of pages: hubs and authorities [3]. An authority is a page with original, high-quality content about a given topic, and a hub is a page that collects links to authorities. In the WordPress.com universe, a Discover post like this one is a hub, and the sites it links to are authorities on portrait photography. Great hubs link to great authorities, and a great authority is one that is referenced by great hubs.
Each of these algorithms has strengths and weaknesses. Some are susceptible to link spam, and some may just be too well-known to content marketers who could use it to artificially improve a page’s ranking. Many search engines use a combination of these or similar algorithms with a wide range of other features. What exactly they use is often a secret, and for a good reason: a search engine would become useless if publishers and marketers knew the exact recipe to get top rankings.
What is clear, however, is that the best search engines use continuous testing to improve their algorithms and learn about the relevance of new documents in their collection. In the next post in this series, we’re going to look at how the performance of a search engine is measured, and show a few simple examples of how we’ve improved ours already.
Recommended reading and sources:
[1] Jones et al, A probabilistic model of information retrieval: development and comparative experiments: Part 2, Information Processing & Management 36.6 (2000), pages 809-840
[2] Brin & Page, The Anatomy of a Large-Scale Hypertextual Web Search Engine, article
[3] Kleinberg, Authoritative sources in a hyperlinked environment, Journal of the ACM (JACM), Volume 46 Issue 5, Pages 604-632, article
[4] Manning et al, An Introduction to Information Retrieval, Cambridge UP, 2009, pdf
[5] Liu, Learning to Rank for Information Retrieval, Springer, 2011



Leave a comment