
Welcome to the third part of our mini-series “Intro to Search.” In my previous posts, I’ve discussed the characteristics of great search results and what a search engine looks like from the inside. But, how do we know if our algorithms actually deliver relevant search results? The answer is, of course, by measurement!
There is no single method for measuring search performance. Several factors determine our approach:
- Intentions (the reasons the search engine was built in the first place),
- the available type of data, and
- the amount of data.
Intention
Search engines make archives, inventories, websites, large publishing platforms, and the internet navigable. Different sites take different approaches to optimize their search, based on their needs. For example, a medical database would optimize their search algorithm for relevance. An online shop would optimize for sales. A platform with sponsored content would optimize search to direct traffic to their paying customers.
The WordPress.com Reader’s search engine helps our users find posts most relevant to their interests. We know they often go for broad, inspirational search terms, perhaps seeking inspiration or a community in which to grow their own writing or photography.

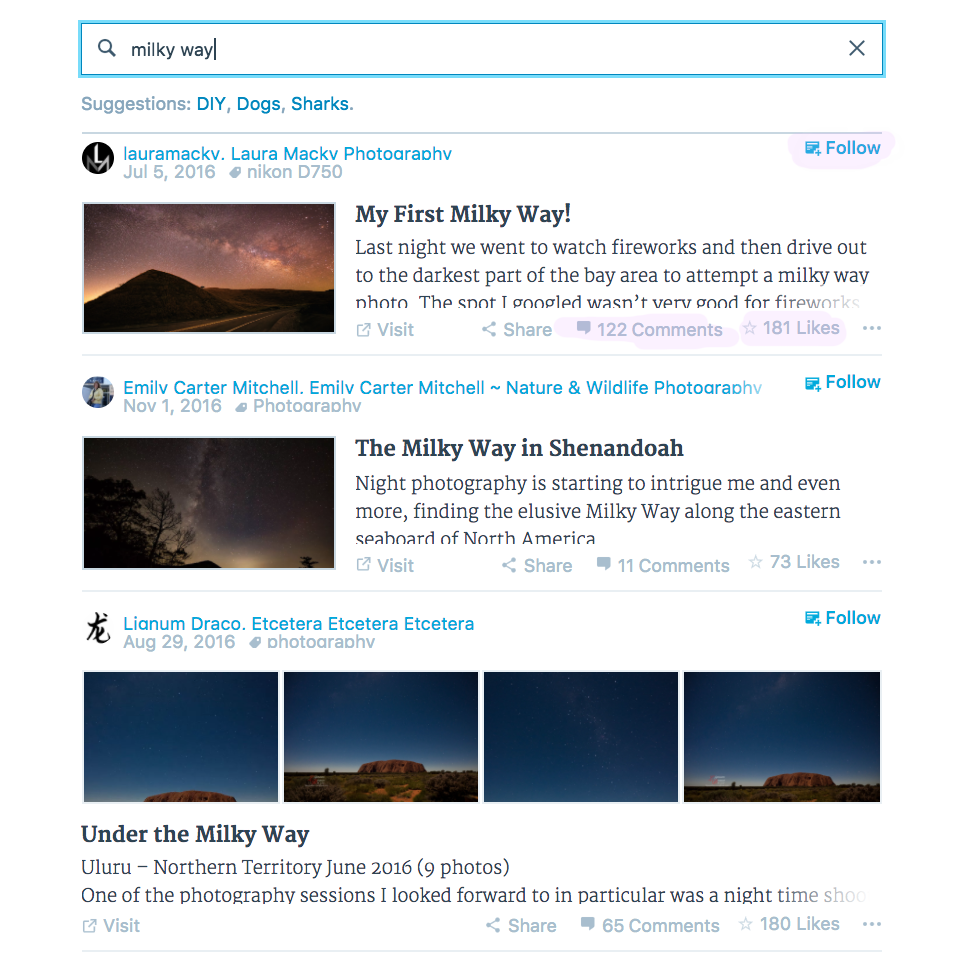
But how do we know we have connected our users with relevant posts? On WordPress.com, liking posts, commenting, and following sites signify that readers have found content they care for. Additionally, these actions encourage writers on our platform to carry on with their craft. Like and comment counts in the WordPress.com Reader help others to identify the most popular posts. For these reasons, we use likes, comments, and site follows to inform our search engine performance measurement.
Types of data for optimization
Search engines try to find the most relevant posts, documents or websites for every search query. Thus, to measure search engine success, we need to know which documents people perceive the most useful!
Ideally, we would have human judgments for many documents. These judgments can be obtained in different ways. Following the definitions in Liu’s book Learning to Rank for Information Retrieval, there are:

Pointwise rankings: judges are presented with a search term and a document and are asked to rank the document’s relevance on a scale. The judgment will always depend on the search query; a great result for “mountain” may not be relevant for “island.”
Pointwise ranking provides the richest source of information for search algorithm optimization. It can be used to infer the order of documents by relevance but also informs us how much more relevant one document is than the other.

Listwise rankings: judges are given a search term and a number of documents. Their task is to sort the documents by relevance with respect to the search term. Unlike in pointwise ranking, they do not need to provide a score for each document.

Pairwise rankings: judges are shown a search term and a pair of documents from which they have to pick the most relevant for the search term.
Of these three options, pairwise ranking is the easiest but provides the least amount of information.
Gathering ranking data from human judges can be time-consuming and costly; hiring people costs money, crowd-sourcing necessitates engineering time to implement quality checks, and asking users to give detailed feedback on search results makes the search interface much more tedious to use.
In internet applications, one can use surf data to replace explicit feedback. Every time a user opens a search result, they are saying “this is relevant to my search query.” Of course, users will always be biased by the order in which the search results are displayed. Surf data is thus best suited to infer pairwise preferences between documents that were shown directly next to each other on the results page. A bit of randomization to exchange the order of closely ranked documents can help to collect better data.
But, what do we do with a list of pairwise rankings? We use them to derive a set of allowed permutations. Imagine that we have three documents A, B, and C and we know that C is more relevant than B. We then know that the permutations ACB, CBA, and CAB are in agreement with this preference. There are several metrics for the agreement between two lists of 


Here, 


Given a prediction, like CAB, we can calculate Kendall’s 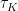



Size of the data
A new search engine may not have enough historical data to derive rankings for a large enough number of documents or searches may be too concentrated on just a few popular terms. Even with a fairly large number of users, it is possible to end up with a relatively small amount of data per query if the search engine, like ours, displays results as you type. With search-as-you-type, some users may already find what they are looking for before they complete typing their search term.
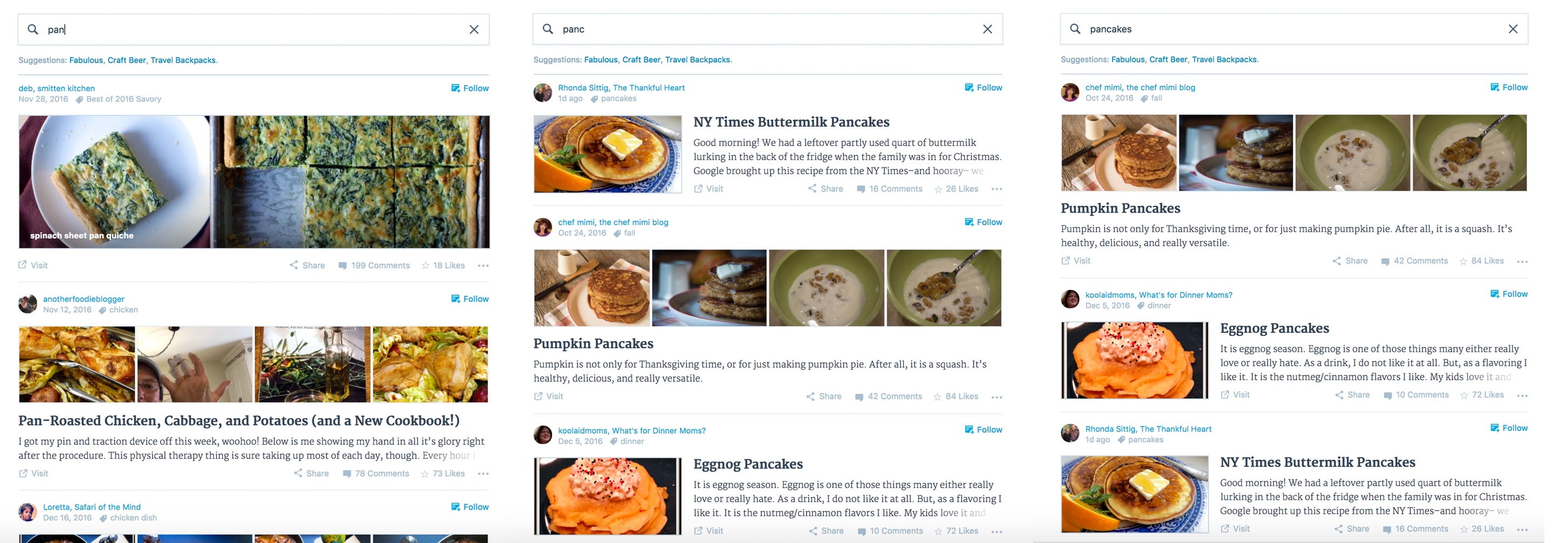
As a result, our data contains more search terms but fewer requests per term: For every search term that was entered by more than 1,000 unique users in the WordPress.com Reader, 14,000 terms were submitted by only a handful of users.
Aggregate metrics are an alternative when there is not enough data (yet) to make a detailed assessment of the document ordering. For example, when we do not have data for a more detailed study, we look at the rate of users who like or comment or follow a site from one of the top 10 search results.
Whichever metric you choose for your optimization, keep in mind to average over a large number of search terms. What works for one search term may not work for the other; likes may be an important signal for great photo posts, comments may be a better one to find discussions about politics.
Does this all sound fun to you? Do you like tinkering with ElasticSearch? Apply to become a Search Wrangler in our fun, distributed, and international Data team.
Recommended reading and sources:
[1] Manning et al, An Introduction to Information Retrieval, Cambridge UP, 2009, pdf
[2] Liu, Learning to Rank for Information Retrieval, Springer, 2011
[3] Ebay Tech Blog, Measuring Search Relevance, post
[4] Li, A Short Introduction to Learning to Rank, IEICE TRANS. INF. & SYST., VOL.E94–D, NO.10 OCTOBER 2011, pdf




Leave a comment