
Last month, we introduced pipe, the Automattic machine learning pipeline.
A generalized machine learning pipeline,
pipeserves the entire company and helps Automatticians seamlessly build and deploy machine learning models to predict the likelihood that a given event may occur, e.g., installing a plugin, purchasing a plan, or churning.
Our goal with pipe is to make sure that anyone at Automattic can build and deploy simple, reliable, and reproducible machine learning models.
With reproducibility and generalization as its driving ideals, pipe has three main functions:
- Getting relevant data for eligible sites and users, and turning data into features,
- Building and evaluating machine learning models, and
- Generating predictions we can use for product and marketing efforts.

Getting Automattic-specific data
At Automattic, because we work with sites and site owners, our data and models usually answer questions about how sites or their owners behave and how they are predicted to behave. When it comes to getting data, pipe has two main flows. It can either accept a list of site or user ids for which to generate data, or it can accept a cohort.
Cohorts
For example, for WordPress.com sites, we have three main cohorts:
site_free: Free WP.com sites. For example, a Day 30site_freecohort would look at a blog’s signup date and would include all blogs that were free in their first 30 days.site_paid: Paid WP.com sites. A Day 30site_paidcohort would be all blogs that have been on a paid plan for 30 days. (Note: they may have registered a year ago, though this cohort only deals with their first purchase date.)site_any: Similar to thesite_freecohort, this group includes all sites who signed up on a given day. But because there isn’t a requirement not to have purchased a plan, this cohort can include both free and paid cohorts.
Let’s say we wanted to predict which Day 30 free sites would upgrade to a paid plan by Day 37. Our cohort would be site_free. We would specify a CLI argument to say that we would like to look at Day 30 sites, another argument that specifies that we’re interested in predicting a plan purchase event, and another argument to set a seven-day conversion window. We would also specify a training date range, let’s say between 2018-01-01 and 2018-05-01.
If we fire up pipe with these specifications, in the background pipe would:
- Get all sites that signed up between 2018-01-01 and 2018-05-01,
- Keep only those that remained free sites for their first 30 days,
- Get features for these sites for their first 30 days, (as 30 is the cohort analysis days for our cohort), and
- Get classification labels denoting wether these sites ended up upgrading in the given seven-day conversion window between Day 31 and Day 37.
We would want data only for sites that do not leak any future information and make sure that each site in the training data set has had the same number of days for their conversion window. So if we are looking at Day 37 behaviour of Day 30 sites, we would need to make sure that all sites in our training data set are at least 37 days old.
So there is a lot of product-specific date arithmetic going on in the background to be able to set training date ranges that make sense considering the user-specified cohort and conversion window, which is why it is best to have central and general pipelines to handle these tedious tasks.
We could also build models for sites without specifying cohort analysis days. We could say “build a model for eligible sites’ likelihood to purchase a plan in the next seven days,” in which case we would get the given sites’ activity until an analysis end date of let’s say 2018-10-01 and generate labels based on whether or not they purchased a plan by 2018-10-08. We call these untimed cohort projects because they do not specify a time for a cohort, like Day 30 or Day 15 cohorts — it just says “any eligible site,” which in our case would be any site that was on a free plan on 2018-10-01.
Adding new cohorts to pipe is an easy dev or analyst task. While the example shows WordPress.com cohorts, any product in the Automattic family could have its own cohort. We can also specify our list of sites to be used as training data as a custom list of IDs and bypass the cohort querying.
Conversion queries
Buying a plan is not the only conversion event for which pipe can build models. Just like cohorts, we can add conversion events in “plug-and-play” fashion. We have some conversion queries already added to pipe such as a site going from a free plan to a paid plan, or the opposite. Conversion queries come with a base cohort to which they are applied. The cohort specifies site eligibility, and conversion specifies the labels we get for our training data set.
For example, a conversion query about going from a free plan to a paid plan makes sense only on a free cohort. We would specify that as: site_free:free_to_paid, where the part before the colon specifies the cohort and the second bit specifies which conversion event we are interested in for that cohort. Or we could build a churn model by specifying site_paid:paid_to_free.
We also have a dynamic conversion query called event_like. Events done by our users and blogs are logged to an events table. (So far there are 5-6,000 distinct logged events.) By joining onto this table, we are able to dynamically generate a conversion query for any event that we log.
For example, we can generate labels for free or paid sites to see their likelihood to publish a post: site_any:event_like_post_publish or for paid sites to see their likelihood to install or use the simple payments button: site_paid:event_like_simplepayments. This dynamic conversion query does a regex search across all our logged events for the term simplepayments. We can build thousands of machine learning models by only changing one CLI argument so that the term being searched for across our events changes while the search structure remains the same.
Importance of generalization and independent steps
This is made possible because we treat the list of eligible sites separately from the label that these sites get based on whether they convert or not. So once we have a cohort definition, we get the list of eligible sites. Once we have a list of eligible sites and an analysis date period, we generate labels. Generating labels for a classification task in machine learning (ML) is as easy as just querying an events table to see if the given site performed the given event in a given time period.
By making each step of the ML process more-or-less independent from the ones preceding it, we can use the same logic across many different use cases without any need to write more code.
Besides not having to write code, this makes our models reproducible, ensuring that all models are built based on the same set of general rules.
Turning data into features
At Automattic, to generate features, we look at things like logged events done by users or sites, traffic that a site receives, whether they have enabled certain features like Publicize, etc. We have about 20 queries that dynamically generate about 10-30,000 features. (The kind of data you would get for an ML pipeline would change from company to company.)
For example, for us, sites with paid plans are able to perform events that sites with free plans are not. This means that we need to flag our feature queries based on whether they are getting data for a paid or a free or a mixed cohort and automatically provide lists of eligible features we can look at per project.
However, there are some general governing ideas about the difference between data and features. Data is messy and usually the more data you have the better it is, though this is not the case for features. When it comes to features, sometimes less is more — which is why feature reduction algorithms exist. Features should be compact, informative, and representative; they are usually informed by domain expertise.
Features are derived from data. For example, if you look at when a site registered, the site registration date would be your data. But the specific date that a site registered would also be absolutely useless information when building a model. So you turn that one piece of data into features by looking into context: Which day of the week did the site register? Which week of the month? Which quarter of the year?

This way, your model can learn insights such as “sites registering on Mondays are more likely to churn,” or “sites registering on December are more likely to buy a plan.”
One of my favourite examples for the same issue of data representation comes from Deep Learning by Ian Goodfellow, in which the same geo data is plotted using cartesian vs. polar coordinates:
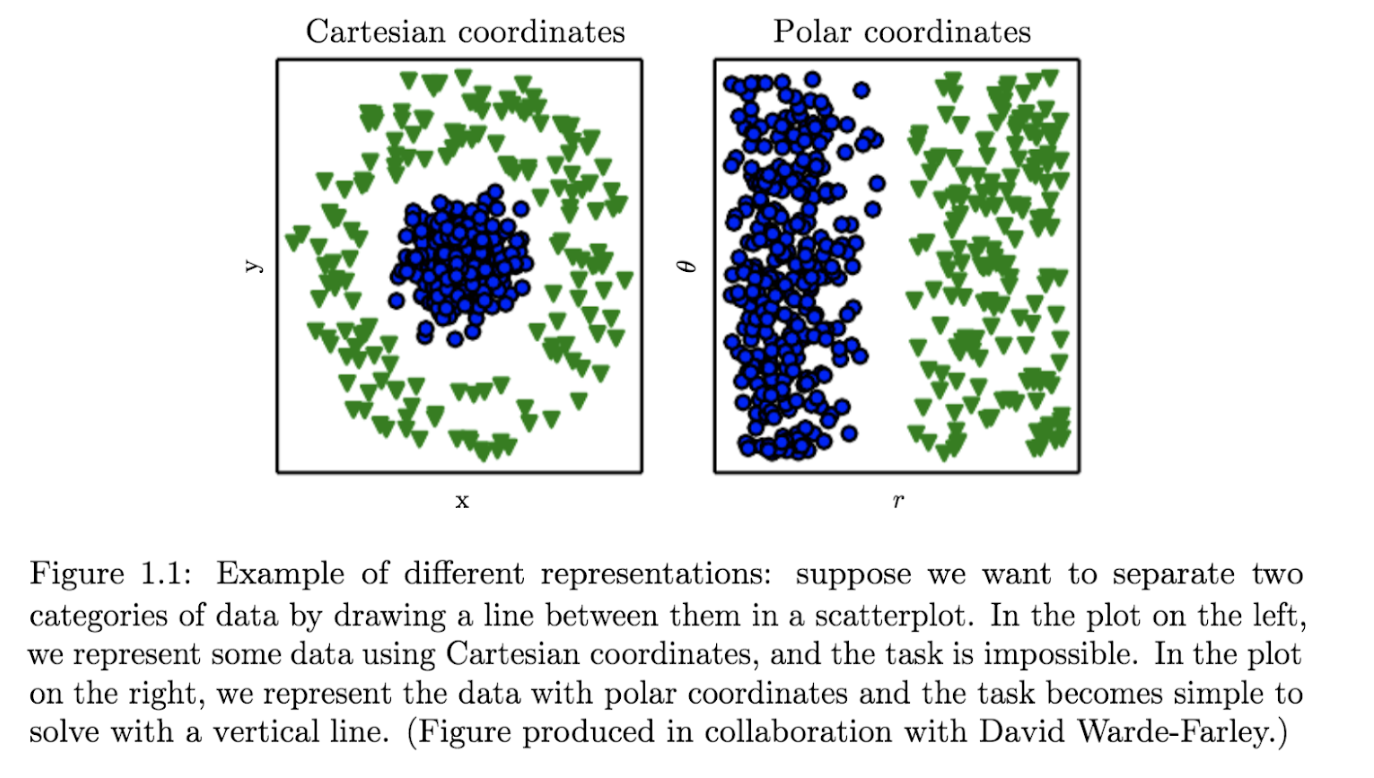
Hate data, love features
Once we have our training data that includes eligible sites, their eligible features and their labels, we can build our ML model. pipe uses libraries like sklearn, sklarn-pandas, and hyperopt during the model building process. We do cross validation, some light parameter tuning, and we are currently introducing better feature pre-processing via Pipelines. We are currently only building simple Random Forests as they perform well enough for our needs, but will also be looking into other models that can provide feature importances.
Feature importances show which features contributed information gain to the model. We have discovered things such as Portuguese speaking users being more likely to churn, or signup for the day of week being a contributor to a site’s likelihood to churn from looking at feature importances. However, usually they do not provide huge insight.
They do serve a better purpose though and we can use a threshold for feature importance to train better models by getting rid of features that do not contribute much to a model’s performance.

As Yanir and I did early prototyping, we kept coming back to the same idea: the importance of well-defined features. Well-defined, well-tested, generalized features informed by domain expertise make all the difference. Especially since data can be so messy, gruesome, and tedious to work with, I have been pretty open about my distaste for data (but love of features!). 🙂


Output of pipe
All pipe projects are initiated with the following arguments from the CLI:
- Project name,
- Cohort analysis days (if we are doing timed cohort projects), or list of IDs and a training analysis end date (if we are working with untimed cohorts),
- Conversion event to use to generate labels,
- The conversion window in which sites have to perform the given conversion event,
- Date range to use for training data generation, and
- A training sample size if we would like to randomly sample from all eligible sites when generating features and building models.
Then pipe does its magic and produces the following for each project:
- A pickled dataframe that has the raw data for training including labels,
- A pickled dataframe that has the processed data generated from the raw data,
- A pickled model file that has a model built from the generated features along with information about the probability threshold value used for classification,
- A model information file that has performance metrics about the model, confusion matrices for our classification problems, and feature importances from the model as a dataframe,
- An Impala predictions table created and filled with the day’s predictions. (This is updated daily when the project is deployed via
pyyarnto our Hadoop clusters. The table shows the raw prediction score for a classification task, as well as the 0/1 classification based on the model threshold), - An Impala daily evaluations table which has information about how the model performs on live data for the day’s eligible sites and has all our ML metrics of interest updated on a daily basis,
- For classification, we look at the confusion matrix in its raw and normalized forms, and log number and ratio of true and false positives and negatives,
- We use informedness as our main classification metric, which is
1 - true_positive_rate + true_negative_rate, - We also look at the ROC AUC score and use ROC AUC to do offline model optimizations,
- An Impala A/B test group assignment table, which we will explain in a separate data.blog post, and
- An info JSON file that has information about the project as well as paths to the above files and tables generated. (This makes sure that by just having access to the info JSON file you can reproduce the exact same model by running a new
pipeproject with the settings saved in the JSON file.)

Every time a project is created or changed, pipe syncs the locally created files on our sandboxes (that are connected to our Hadoop clusters) with HDFS so that everything is centralized on our Hadoop clusters and its distributed file system.
As mentioned, we use CircleCI, Conda, pytest, pyyarn, Impala and other — in my slightly hyperbolic opinion life-changing — tools, practices, and technologies to make things extremely convenient, and we currently run about 150 tests (but add more with each change) to ensure reliability and robustness.
When a new pipe release is deployed to our clusters, the deployment also uploads the Conda environment, and our Oozie jobs run the daily flow in a pyyarn container using the uploaded environment, which means that some of the most tedious parts of deploying models in business environments are taken care of.
The case for ML pipelines
Huge amount of work to build a data driven product… a small slice of that is building machine learning models. The rest of that whole pipeline is broad…. It includes “how can we define the problem we’re actually trying to solve?”, “what’s the raw data that we’re going to be running on?”, “how do I clean and prepare that?”, “what labeled data can I use for training the algorithm? do I have to bring in a team of people to do the labeling, and what tools do I need to build to enable them?” All of that stuff. Then, there’s all these questions about “how does that model fit into my overall application and code base? and then the outputs of it”; “where does it fall into the user experience? and what things do I need to show so that people understand the outputs of the model to make it interpretable?” There’s this whole universe of stuff that isn’t building the model but it’s very related to building the model. It is technical and challenging to figure out.
(Source)
To be honest, building a machine learning pipeline did not arise from a specific need. I used to call pipe “The ML pipeline no one asked for.” However, especially as we kept on working on it, it became obvious, at least to me, that if you would like to use ML models in your business then investing resources in a generalized pipeline upfront will save you from months of work per project. Of course, there will be ML projects that can’t fit into pipe or a similar pipeline as they will require bespoke, more specific modelling work. We have teams at Automattic working on such models, too.
But — for the more general questions that most companies deal with — an end-to-end pipeline is, I believe, the better option because:
- Every step of building a data product is rife with opportunities for introducing bugs or making the wrong assumptions. This is the nature of our work. You generally don’t realize these until after you have put in weeks of work, and sometimes not even then. You may realize one wrong assumption and fix it but the data scientist after you may easily make the same mistakes.
- A lot of the work is about getting things off your local computer to actual production. Ideally, there is one clear path to production, if one ML model is able to do it, the same path should be provided for all other projects, too. This will save a tremendous amount of effort and time in the long run, as well as ensure that the path to production is well-maintained as all ML projects at the company use it.
- An ML model without impactful application is useless, and it is hard to estimate impact without building at least a preliminary solution. Being able to build models with the click of a button means it is not a big investment to try out ideas and test impact.
- While data scientists are generally hired to be part statistician, dev, mathematician, frequentist, bayesian, data engineer, and ML practitioner, we are more skilled in some areas than others, so a common effort to provide a general solution will likely produce better results than many one-off efforts even if it takes more time initially.
- The problems you have to solve with these types of ML and data products are easily generalizable, so it makes sense to generalize the solution, too.
- Less data scientist time spent on dealing with data engineering and pure development means more time to spend on why companies generally hire data scientists: turning the model results into good business decisions.
There seem to be quite a few businesses that provide ready-made ML pipelines for companies, however, as you can see from the way something like pipe is built, an ML pipeline is usually very tied to business logic.
While some solutions can help automate the model training and tuning part of the process, it is also the part of pipe that we spend the least amount of time on. Model training in pipe is quite underdeveloped and boring, but while we are working on making it better and a bit more exciting, we found that it is actually good enough as it is. Most of our time is spent on getting our business logic into the system through defining cohorts, features, and conversion events and engineering it all together to form a clear path to deployment.
Up next
In the next installment in the pipe series for data.blog, we’ll look at using predictive models in Marketing, experiment setups for online evaluation, uplift modeling, and building models that are useful as opposed to just accurate.




Leave a comment