
At Automattic, A/B tests help designers, marketing specialists, and developers to test their assumptions, measure the impact of new features, and make data-informed decisions. Our data science team built a tool, called “Hypotheses” to automate data collection for as well as planning and analysis of A/B tests. In this post, you will learn what A/B tests are and how our internal tool makes them easier.
Every A/B test is an experiment, similar to ones used to prove that a new medicine benefits patients. When the feature or change is ready to ship we initiate an A/B test where users are randomly divided into two groups, usually called test and control. For the duration of the test, only the users in the test group see the new feature or change. We use the data to make an informed decision about whether the test version performs better and should be made available to all users, or whether it underperforms the original and we need to go back to the drawing board to test new hypotheses.
Imagine, for example, that we wanted to know whether a localized greeting on the homepage is a good idea. We could test for an increase in the number of accounts created. During the A/B test, we would show the localized greeting only to a randomly selected subset of homepage visitors: a visitor from Texas would be greeted with Howdy! if they were assigned to the test group, and with a simple Hi! if they were assigned to the control group. During the A/B test, we count the number of users who visit the homepage and the number of users who create an account in each of the two groups, respectively.
How can we infer whether the new feature improves our conversion rate from the data we collected? Can we draw this conclusion if six out 10 vs. five out 10 users converted with and without the new feature, respectively? And if 60 out 100 vs. 50 out 100 users converted? The answer lies in the statistical analysis of the collected data.
Why did we build a tool?
Prior to our work on this, our colleagues did not have a single place to perform these analyses. Instead, they had to combine several tools. Because we automated some of the tasks all A/B tests have in common, our colleagues can now worry less about math and statistical libraries and focus more on their experimental setup.
I believe that, ideally, my colleagues should spend the vast majority of the time they dedicate to A/B testing thinking about questions such as:
- What do I want to learn from this test, i.e., what is my hypothesis? Good hypotheses are precise and measurable. Examples of good hypotheses are: Algorithm A drives more engagement than algorithm B. or Changing this step in our sign-up flow increases sign-ups.
- What is the target variable that I have to track to verify this hypothesis? For the comparison between two content recommenders, it might be the number of clicks on recommended content. For changes to a sign-up flow, it might be the number of accounts created.
- How do I know how many users have been exposed to the test? This might be the number of users who load a specific page (for example, the one where content recommendations are served) or click a button (for example, a sign-up button).
- Which aspects of the user experience will be different with the test? If the test changes only the last of thirty recommendations or adds an item to the footer of a very long web page, the test might take a very long time before any significant differences can be seen.
- Which users should be in the test? Some A/B tests might be country-specific or target users in a specific vertical. Users who do not belong to this group can dilute the results and increase the amount of data that has to be collected for a conclusive test.
- Is now a good time to perform this test? Split testing is a good safeguard against external influences on your test results, such as seasonal variations. Nevertheless, there are cases in which external factors can influence whether the test results are indicative of future performance or not. If, for example, a marketing campaign is temporarily driving acquisition of one type of user a lot but your feature is designed for a different type, that might make a difference.
- Am I sure that I have all the data I need to analyze this test? It is a good practice to ensure all the correct tracking is in place before the test starts.
Our tool: Hypotheses
Hypotheses enables our colleagues to spend more time on these questions. They can use a web interface to provide data about the A/B test and define a funnel, i.e., a sequence of tracked user events that identify users who are eligible for the test and users who performed the target action. Based on this information, Hypotheses displays the latest conversion rate in the funnel and optionally shows the latest trends in the conversion rate. In this way, our colleagues can at the same time set up the analysis and confirm that data collection is working. Due to this tight integration with our tracking system, Hypotheses is an internal tool that is not available to anyone outside of Automattic. The following screenshot shows how a new A/B test is entered in Hypotheses.

Based on the historical conversion rate, the tool also provides an estimate of how long the test will need to run before an effect can be detected.


From the day an A/B test is registered with the tool, it automatically collects and analyzes the relevant data every day. The results include the conversion rates in test and control group, the significance of the observed difference (if any) between the conversion rates and, based on these, advice how to proceed. We use this opportunity to encourage some best practices. For example, we recommend that every A/B test runs for at least week (or, if needed, multiple full weeks) to account for differences between weekday and weekend users.

 Automattic is a fully distributed company and we communicate through an internal network of blogs, called P2s, and also via Slack. The A/B test analysis tool is integrated into this communication flow. When the latest results are available each day, Hypotheses sends a Slack message with a summary and a link to the latest results to the person who registered the test.
Automattic is a fully distributed company and we communicate through an internal network of blogs, called P2s, and also via Slack. The A/B test analysis tool is integrated into this communication flow. When the latest results are available each day, Hypotheses sends a Slack message with a summary and a link to the latest results to the person who registered the test.

This integration in our communication also allows us to alert the test’s creator in the odd case where the conversion rates are unexpectedly far off. Sometimes, a new feature has unforeseen side effects (a.k.a. bugs) that prevent users from converting or, in fact, having a good user experience. With Hypotheses, we can detect these cases and alert the creator of the A/B test.
Bayesian and frequentist A/B tests
Sending daily updates is only possible because our tool is a Bayesian tool. In statistics, the two major schools of thought — frequentist (see, for example, Neyman, Venn), and Bayesian (see, for example Bayes, Jeffreys) — interpret probability in a different way.
Frequentists interpret probabilities as the frequencies that would be observed if an experiment ran infinitely or was repeated an infinite amount of times. Frequentist methods give guarantees about what would happen in this very long run. For Bayesians, probabilities are subjective degrees of belief that are updated in the light of new data: our A/B tests start with the prior assumption that both variations are equally likely to outperform the other. As we collect data, we update this belief based on the new information we have collected. This New York Times article is an accessible introduction to Bayesian statistics with a comparison to the frequentist approach.
Like two different philosophies, neither is plain right or wrong, and I believe that, if done correctly, both can be applied to A/B tests. In fact, I used a frequentist analysis in my PhD thesis on searches for astrophysical neutrino sources. In our fast-paced company, we have highly autonomous decision makers. They are as concerned about giving every user the best possible experience as about doing statistics correctly. As a result of this, I find Bayesian A/B tests better suited, as they’re more intuitive and do not require a fixed sample size.
We use the Bayes factor to decide whether we trust an observed increase in conversion rate. Or, in other words, we test the hypothesis that the true conversion rate with the changes 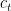


If A and B are two sets, then the probability to be both in 

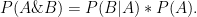
Here, 
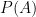

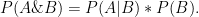
The notation is the same but the roles of

This is Bayes’ theorem. Re-interpreted to express the probability that a hypothesis 

Here, 



The Bayes factor
In A/B tests, we’re interested in comparing the probability for our hypothesis 
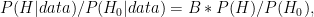
or, if we believe that
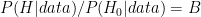
with

The more support for the hypothesis in the data, the bigger the Bayes factor. A small Bayes factor, in turn, shows that the data provides evidence in favor of the null hypothesis, i.e., a small Bayes factor implies that the change does not increase conversion.
Using the Bayes’ factor as a decision criterion is a choice. There are various other ways in which Bayesian A/B tests can be implemented. One other way is described on my colleague Yanir’s blog.
One of the many plans we have for the future of Hypotheses includes adding richer analytics. At the same time, we are collaborating with one of our designers to make the user interface shine. We are also exploring opportunities for automatic dashboard creation and easier sharing of the A/B test results.




Leave a comment