
Our customers do not think of support as isolated chats.
They think in terms of things they are trying to get done: connecting a domain, changing the look of a site, launching a store, fixing checkout, recovering access, or understanding a bill.
That creates a challenge for an AI support assistant. If a customer returns and says:
Let’s continue transferring my domain
Then the assistant needs more than the latest message. It needs to know which domain, what the customer was trying to do, what had already been tried, and what remained unresolved.
That was the starting point for cross‑conversation recall in WordPress.com’s AI Support assistant. We wanted it to retrieve useful context from previous conversations so customers would not have to explain the same problem again.
But this immediately raised an interesting data problem:
What is the right unit of memory?
A single message is usually too little. It may point to the problem, but it rarely contains all the necessary information. A whole chat is often too much. It contains the problem, but also everything around it: greetings, detours, repeated instructions, dead ends, and sometimes multiple unrelated tasks.
We needed something in the middle: smaller than a transcript, richer than a message, and structured around what the customer is trying to accomplish.
Episodes are the middle layer
A support interaction usually has a session‑based shape. A customer arrives with a goal: connect a domain, change a theme, or launch a store. During that session, they provide context, answer clarifying questions, try steps, make decisions, and either reach an outcome or leave with something unresolved.
That session is often a coherent unit of work, which we call an episode. An episode does not always map perfectly to a whole conversation: one conversation may contain multiple episodes, and one larger customer journey may span several conversations. But the episode is a useful first memory unit: a bounded stretch of interaction with a goal, context, actions, and an endpoint.
For example, a long support exchange about DNS might become:
{ "topic": "Custom domain connection blocked on DNS propagation", "key_facts": [ "Customer is connecting example.com from GoDaddy.", "Customer changed the nameservers earlier today.", "Customer says the site still isn't loading after DNS change." ], "decisions": [], "unresolved": [ "DNS propagation: blocked — customer will check tomorrow." ], "friction": ""}
This summary is much smaller than the original chat session, but it preserves the information that matters when the customer comes back later.
Finding the boundary of an episode
The next question was where one episode should end and another should begin.
In theory, we could detect this semantically: watch for topic shifts, changes in customer goal, resolved blockers, or movement from one product area to another. That is likely what this system will evolve into over time.
For a first version, though, gaps in interactions gave us a practical starting point.
If a customer disappears for five minutes, they may simply be trying a suggested fix. If they disappear for several hours, they may be starting a new support session.
Choosing the right episode boundary matters because summarization is not lossless. If the window is too wide, the model has to compress several unrelated goals into one record, which creates summary drift: vague, blended memories that are less useful for recall.
Very short thresholds split coherent work into fragments. A customer might step away to update DNS records, test a setting, or check their inbox, then return with the result. That should usually remain part of the same episode.
Very long thresholds merge separate tasks. A customer might come back hours later to ask about a different part of their site, and treating that as the same memory makes the summary less precise.
We tested this against real WordPress.com support chat distributions and found that roughly 30–45 minutes was a useful practical boundary.
So the first layer is deliberately simple:
messages → time-gap episodes → structured summaries
Time‑gap detection is not a complete theory of customer intent. It is a cheap, explainable way to create useful first‑level memory units. Those units can then be merged, ranked, archived, or rolled up into higher‑level memories later.
From chats to episode summaries
At a high level, the pipeline looks like this:
Raw conversation logs
↓
Find time‑based windows of interaction
↓
Generate structured episode summaries
↓
Store vectorized summaries for search and retrieval
↓
Use summaries for recall, next steps, and analysis
The important shift is the data model. Instead of treating support history as a sequence of messages, we create a structured memory layer above it. Each episode is grounded in the original conversation, but easier for an assistant to retrieve and use.
Cross‑conversation recall becomes retrieval over these clean units of customer intent rather than arbitrary chat fragments.
A returning customer might ask:
Can we continue with the domain thing?
The support AI can retrieve the relevant episode, and that gives the assistant enough context to continue naturally:
Yes — last time you were connecting your domain from an external registrar. We had updated the DNS records, so the next thing to check is whether propagation has completed.
That is the core benefit: the assistant can act on a compact record of the previous support work, rather than reconstructing intent from raw messages.
What this unlocks
The practical value of episodes is their granularity. They are detailed enough to preserve intent, but small enough to retrieve, reason over, and pass between systems.
That makes several kinds of assistance easier:
- Continuation: “Can we pick up where we left off?”
- Next‑step prompts: “You have an unfinished checkout setup from your store launch. Would you like to continue with that?”
- Human handoff: “The customer is trying to connect a third‑party domain. DNS records were changed, but resolution is still failing.”
- Search and retrieval: recall can search compact, semantically meaningful episode summaries, instead of raw transcripts.
Episode summaries can also become a source for derived memory. For readers familiar with PARA – Projects, Areas, Resources, and Archives – there is an obvious connection: a sequence of episodes may indicate an active project, an ongoing area of concern, a reusable resource, or work that can be archived. In our model, the episode remains the grounded record of what happened; PARA‑style notes are extracted from episodes and can evolve as more episodes arrive.
What episodes reveal at scale
Episode summaries also make aggregate analysis cleaner.
Raw chats are noisy, episode summaries are closer to customer intent. That makes them easier to cluster into themes such as domain setup, site editing, checkout configuration, migrations, billing, or account access.
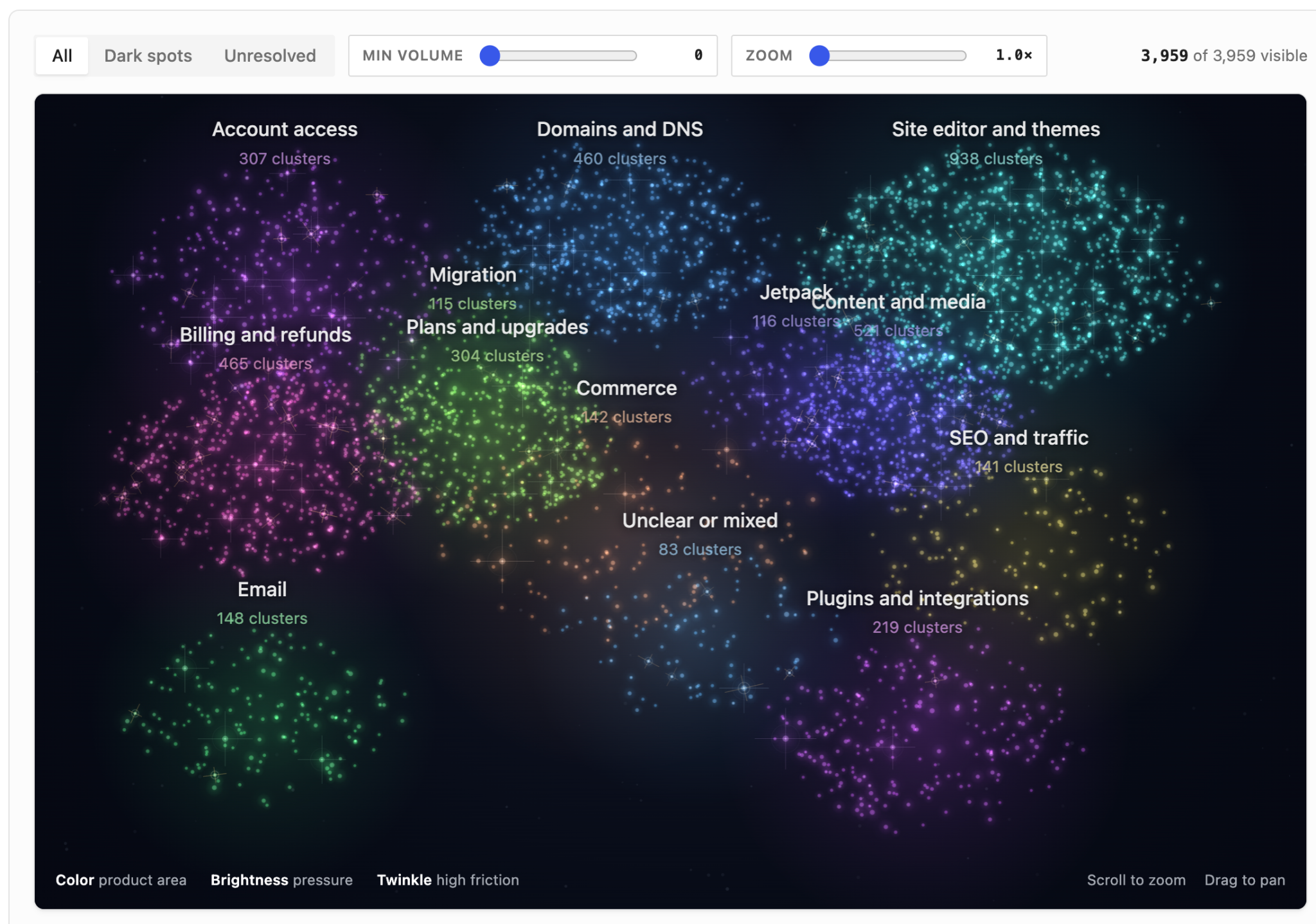
This can reveal product friction more clearly than raw transcript analysis. For example, a cluster of domain episodes might show that customers are not just “asking about DNS”; they are repeatedly returning after changing records because they cannot tell whether they are waiting for propagation or whether something is misconfigured.
Where we go from here
This work started with cross‑conversation recall, but episode summaries now give us a practical memory layer to improve and reuse.
The next step is to keep improving the pipeline itself: better episode boundaries, better summaries, and better ways to decide which derived memories should stay active, become reusable context, merge into larger goals, or quietly expire.
The episode layer can also help us understand support patterns at a higher level. If episode clusters show repeated friction around domains, checkout, site editing, or migrations, those patterns can help PMs and Happiness Engineers understand where customers are getting stuck and whether product changes reduce repeated support episodes.



Leave a comment