If you have read our analysis on the communities of WordPress.com and would like to know more about the methods behind it, then keep on reading! In this — slightly more technical — post, I will show how we constructed, filtered, projected, and clustered a network around WordPress.com users and blogs.
Building the Network of WP.com
People on WordPress.com create and engage with content. A user can write, like, reblog, or comment on a post, and follow or create a blog. Our goal is to turn these interactions into a network of users and sites.
Currently, we work with a network that has three main kinds of nodes: posts, blogs, and users. When a user creates a post, she can create multiple ties; first, a tie is created between the user and the post — the user authored a post, an IS_AUTHOR() type tie is created. A second tie is created between the blog and the post — the post appeared on the blog, an IN_BLOG() type tie is created. Another tie is created between the user and the blog — the user becomes a contributor to the blog, so an IS_CONTRIBUTOR tie is created, and so on.
Whenever a user engages with a piece of content — meaning likes, reblogs or comments on it — she creates a tie between herself and the post that she engaged with. This tie then can be further extended to a relationship between the engaged user and the author of the post, as well as a relationship between the engaged user and the blog that the post appeared on. In this project, of the multitude of options, I am only looking at relationships that a user creates between herself and a blog by liking a post on the given blog.

Data and Technical Stuff
Our technical stack for graph analysis consists of a combination of Scala, PySpark, and Hive running on Hadoop clusters; as well as ElasticSearch for some pre- and post‑processing — we also use Neo4J for offline in‑depth analyses.
Projecting the Graph
In its current form, the WP.com network is a multipartite graph, which means that the network has multiple classes of nodes. There can be relationships between nodes of different classes, but not between nodes of the same class — there can be an explicit relationship between a user and a post, as when a user likes a post, but there can’t be a relationship between a post and a post.

Using a method called graph projection, we can show the implicit connections between the nodes that belong to the same class in a bipartite network.
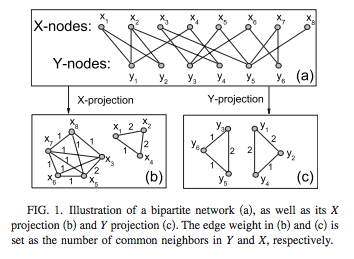
Defining the weight of the edges between the nodes in the projected graph is not a straightforward task. After a lot of testing and iteration, we used a weighted and directed version of Newman projection, where the strength of the tie between a blog to another one also takes into account how many other blogs the given user liked. If a user liked only two blogs, then the strength of the tie between those two blogs are stronger than if a user liked three blogs.
The projection gave us a network with 3.5 billion+ edges and thanks to our technical stack, we were able to filter it to its most important top 20 million edges before running clustering algorithms on it. (I can tell you that it wasn’t a painless process to work with that many nodes and edges, though!)
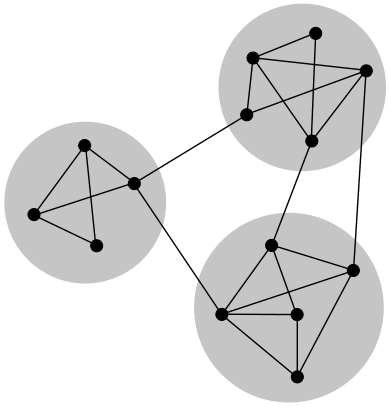
Clustering the Graph
In order to see what kind of different community groups there are, we needed to identify clusters in the social network and show groups of nodes that are more similar to each other (which, in our case, roughly means that they were liked by the same people) than they are to the rest of the network. These groups are called communities, with each blog in the network belonging to a given community of blogs that are enjoyed by a similar group of users.
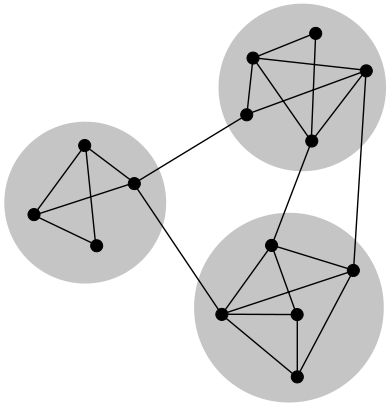
Of the various existing graph clustering algorithms, we picked a Scala implementation of Louvain modularity to run on our filtered graph. An important thing to remember here is that if we don’t pre‑filter the graph to include only blogs from one language (which in our case was English), then we will have very biased clustering, where blogs of the same language will group together, since they will mostly be liked by similar people.
At this point, our initial graph with 3.5 billion edges between English-language blogs has been filtered down to the top 20 million edges with the clustering giving us a subset of 109,099 unique blogs that belong in 428 non-overlapping communities.
You can read about the initial results of our community mapping here!




Leave a comment